

 Реферат: Распределенные алгоритмы
Реферат: Распределенные алгоритмы
(6) Обнаружение тупиков и их разрешение. Если процессы должны ждать друг друга (как в случае, если они разделяют ресурсы, и также, если их вычисления полагаются на данные, обеспечиваемые другими процессами), может возникнуть циклическое ожидание, при котором не будет возможно дальнейших вычислений. Эти тупиковые ситуации должны определяться и правильные действия должны предприниматься для того, чтобы перезапустить или продолжить вычисления.
(7) Распределенная поддержка файлов. Когда узлы помещают запросы на чтение и запись удаленного файла, эти запросы, могут обрабатываться в произвольном порядке, и отсюда должна быть предусмотрена мера для уверенности в том, что каждый узел наблюдает целостный вид файла или файлов. Обычно это производится временным штампованием запросов, также как и информации в файлах и упорядочивание входящих запросов по их временным отметкам; см., например, [LL86].
1.1.5 Многопроцессорные компьютеры
Многопроцессорный компьютер это вычислительная система, состоящая из нескольких процессоров в маленьком масштабе, обычно внутри одной большой коробки. Этот тип компьютерной системы отличается от локальных сетей по следующему критерию. Его процессоры гомогенны, т.е. они идентичны по аппаратуре. Географический масштаб машины очень маленький, обычно порядка метра или менее. Процессоры предназначены для совместного использования в одном вычислении (либо чтобы повысить скорость, либо для повышения надежности). Если основное назначение многопроцессорного компьютера это повышение скорости вычислений, то он часто называется параллельным компьютером. Если его основное назначение – повышение надежности, то он часто называется система репликации.
Параллельные компьютеры подразделяются на одно-командные много-поточные по данным (или SIMD) и много-командные много-поточные по данным (или MIMD) машины.
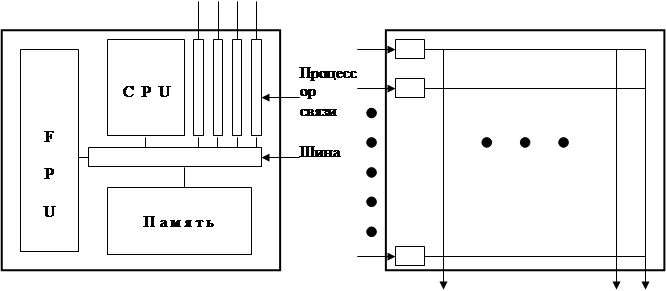
Рис. 1.3 Транспьютер и микросхема маршрутизатора
SIMD машины имеют один интерпретатор инструкций, но команды выполняются большим числом арифметических блоков. Ясно, что эти блоки имеют недостаток автономности, которая требуется в нашем определении распределенных систем, и поэтому SIMD компьютеры не будут рассматриваться в этой книге. MIMD машины состоят из нескольких независимых процессоров и они классифицируются как распределенные системы.
Процессоры обычно оборудуются специальной аппаратурой для коммуникации с другими процессорами. Коммуникация между процессорами может иметь место либо через шину, либо через соединения точка-точка. Если выбрана шинная организация, то архитектура масштабируема только до определенного уровня.
Очень популярным процессором для разработки многопроцессорных компьютеров является транспьютер, разработанный Inmos; см. рис. 1.3. Транспьютер состоит из центрального процессора (CPU), специального блока с плавающей точкой (FPU), локальной памяти, и четырех специальных процессоров. Чипы очень хорошо подходят для построения сетей степени 4 (т.е. каждый узел соединен с четырьмя другими узлами). Inmos также производит специальные чипы для коммуникации, называемые маршрутизаторами. Каждый маршрутизатор может одновременно обрабатывать трафик 32 транспьютерных соединений. Каждое входящее сообщение просматривается на предмет того, по какой связи оно может быть перенаправлено; затем оно направляется по это связи.
Другой пример параллельного компьютера это система Connection Machine CM-5, разработанная Thinking Machines Corporation [LAD92]. Каждый узел машины состоит из быстрого процессора и обрабатывающих блоков, таким образом, предлагая внутренний параллелизм в добавление параллелизму, происходящему благодаря наличию нескольких узлов. Так как каждый узел имеет потенциальную производительность 128 миллионов операций в секунду, и одна машина может содержать 16384 узлов, полная машина может выполнять свыше 1012 операций в секунду. (Максимальная машина из 16384 процессоров занимает комнату 900 м2 и скорее всего очень дорогая.) Узлы СМ-5 соединены тремя точка-точка коммуникационными сетями. Сеть данных, с топологией толстого дерева, используется для обмена данными по технологии точка-точка между процессорами. Сеть управления, с технологией бинарного дерева, осуществляет специальные операции, такие как глобальная синхронизация и комбинирование ввода. Диагностическая сеть невидима для программиста и используется для распространения информации о вышедших из строя компонентах.. Компьютер может быть запрограммирован как в режиме SIMD, так и в (синхронном) MIMD режиме.
В параллельном компьютере вычисления поделены на подвычисления, каждое осуществляется одноим из узлов. В репликационной системе каждый узел проводит вычисление целиком, после чего результаты сравниваются для того, чтобы обнаружить и скорректировать ошибки.
Построение многопроцессорных компьютеров требует решения нескольких алгоритмических проблем, некоторые из которых подобны проблемам в компьютерных сетях. Некоторые из этих проблем обсуждаются в этой книге.
(1) Разработка системы передачи сообщений. Если многопроцессорный компьютер организован как сеть точка-точка, то должна быть разработана коммуникационная система. Это обладает проблемами подобными тем, которые возникают в разработке компьютерных сетей, таким как управление передачей, маршрутизация, и предотвращение тупиков и перегрузок. Решения этих проблем часто проще, чем в общем случае компьютерных сетей. Проблема маршрутизации, например, очень упрощена регулярностью сетевой топологии (например, кольцо или сетка) и надежностью узлов.
Inmos С104 маршрутизаторы используют очень простой алгоритм маршрутизации, называемый внутренней маршрутизацией, которая обсуждается в подразделе 4.4.2, он не может быть использован в сетях с произвольной топологией. Это поднимает вопрос могут ли использоваться решения для проблем, например, предотвращение тупиков, в комбинации с механизмом маршрутизации (см. проект 5.5).
(2) Разработка виртуальной разделяемой памяти. Многие параллельные алгоритмы разработаны для так называемой модели параллельной памяти с произвольным доступом (PRAM), в которой каждый процессор имеет доступ к разделяемой памяти. Архитектуры с памятью, которая разделяется физически, не масштабируются; здесь имеет место жесткий предел числа процессоров, которые могут быть обслужены одним чипом памяти.
Поэтому исследования направлены на архитектуры, которые имеют несколько узлов памяти, подсоединенных к процессорам через интерсеть. Такая интерсеть может быть построена, например, из траспьютеров.
(3) Балансировка загрузки. Вычислительная мощь параллельного компьютера эксплуатируется только, если рабочая нагрузка вычислений распределена равномерно по процессорам; концентрация работы на одном узле понижает производительность до производительности одного узла. Если все шаги вычислений могут быть определены во время компиляции, то возможно распределить их статически. Более трудный случай возникает, когда блоки работы создаются динамически во время вычисления; в этом случае требуются сложные методы. Очереди задач процессоров должны регулярно сравниваться, после чего задачи должны мигрировать от одной к другой. Для обзора некоторых методов и алгоритмов для балансировки загрузки см. Гочинский [Gos91, глава 9] или Харгет и Джонсон [HJ90].
(4) Робастость против необнаруживаемых сбоев (часть 3). В репликационной системе должен быть механизм для преодоления сбоев в одном или нескольких процессорах. Конечно, компьютерные сети должны также продолжать их функционирование, несмотря на сбои узла, но обычно предполагается, что такой сбой может быть обнаружен другими узлами (см., например, алгоритм сетевого обмена в разделе 4.3). Предположения, при которых репликационные системы должны оставаться правильными, более строгие, т.к. процессор может производить ошибочный ответ, и то же время кооперироваться с другими при помощи протоколов как правильно работающий процессор. Должен быть внедрен механизм голосования, чтобы отфильтровывать результаты процессоров, так, что только правильные ответы передаются во все время, пока большинство процессоров работает правильно.
1.1.6 Взаимодействующие процессы
Разработка сложных программных систем может быть зачастую упрощена организацией программы как набора (последовательных) процессов, каждый с хорошо определенной, простой задачей.
Классический пример для иллюстрации этого упрощения это преобразование записей Конвея. Проблема состоит в том, чтобы читать 80 символьные записи и записывать ту же информацию в 125 символьные записи. После каждой входной записи должен вставляться дополнительный пробел, и каждая пара звездочек («**») должна заменяться на восклицательный знак («!»). Каждая выходная запись должна завершаться символов конца записи (EOR). Преобразование может быть проведено одной программой, но написание этой программы очень сложно. Все функции, т.е. замена «**» на «!», вставка пробелов, и вставка символов EOR, должны осуществляться за один цикл.
Программу лучше структурировать как два взаимодействующих процесса. Первый процесс, скажем р1, читает входные карты и конвертирует входной поток в поток печатных символов, не разбивая на записи. Второй процесс, скажем р2, получает поток символов и вставляет EOR после 125 символов. Структура программы как набор двух процессов обычно предполагается для операционных систем, телефонных переключающих центров, и, как мы увидим в подразделе 1.2.1, для коммуникационных программ в компьютерных сетях.
Набор кооперирующих процессов становится причиной того, что приложение становится локально распределенным, но абсолютно возможно выполнять процессы на одном компьютере, в этом случае приложение не является физически распределенным. Конечно, в этом случае достигнуть физической распределенности легче именно для систем, которые логически распределены. Операционная система компьютерной системы должна управлять конкурентным выполнением процессов и обеспечить средства коммуникации и синхронизации между процессами.
Страницы: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105
