

 Реферат: Распределенные алгоритмы
Реферат: Распределенные алгоритмы
while ![]() do insert (
do insert (![]() );
);
(*Теперь вычислить приемлемые значения*)
![]()
![]()
while ![]() do insert(
do insert(![]() ,
, ![]() );
);
![]()
end
После получения <ask> от q:
send<val, ![]() > to q
> to q
После получения <val, x> от q:
if такое сообщение не было получено от q прежде
then insert(![]() , x)
, x)
Алгоритм 14.6 алгоритм с быстрой сходимостью.
Алгоритм с быстрой сходимостью, предложенный Махани и
Шнайдером дан как Алгоритм 14.6. Для конечного множества ![]() , определим две функции intvl(A)=[min(A), max(A)]
и width(A) = max(A) - min(A). Алгоритм имеет фазу сбора входов и фазу
вычисления. В первой фазе процесс p просит каждый другой процесс послать свой
вход (“выкрикивая” сообщение <ask>) и ждет
, определим две функции intvl(A)=[min(A), max(A)]
и width(A) = max(A) - min(A). Алгоритм имеет фазу сбора входов и фазу
вычисления. В первой фазе процесс p просит каждый другой процесс послать свой
вход (“выкрикивая” сообщение <ask>) и ждет
![]() единиц времени. После этого
времени, p получил все входы от корректных процессов, также как и ответы от
подмножества сбойных процессов. Эти ответы заполняются (бессмысленными)
значениями
единиц времени. После этого
времени, p получил все входы от корректных процессов, также как и ответы от
подмножества сбойных процессов. Эти ответы заполняются (бессмысленными)
значениями ![]() для процессов, которые не
ответили.
для процессов, которые не
ответили.
Затем процесс применяет к полученным значениям фильтр,
который гарантированно пропускает все значения корректных процессов и только те
сбойные значения, которые достаточно близки к правильным значениям. Поскольку
корректные значения отличаются только на ![]() и
имеется по крайней мере N-t корректных значений, каждое
корректное значение имеет по крайней мере N-t значения,
которые отличаются самое большее на
и
имеется по крайней мере N-t корректных значений, каждое
корректное значение имеет по крайней мере N-t значения,
которые отличаются самое большее на ![]() от него;
от него;
![]() сохраняет полученные
значения с этим свойством.
сохраняет полученные
значения с этим свойством.
Затем вычисляется выход с помощью усреднения значений - все
отклоненные значения заменяются оценкой, вычисленной применением
детерминированной функции estimator к оставшимся значениям. Эта функция
удовлетворяет ![]() , но в остальном
произвольна; она может быть минимумом, максимумом, средним, или
, но в остальном
произвольна; она может быть минимумом, максимумом, средним, или ![]() .
.
Теорема 14.14
Алгоритм с быстрой сходимостью достигает точности ![]() .
.
Доказательство. Пусть ![]() -
значение, включаемое в
-
значение, включаемое в ![]() для процесса r,
когда p превышает лимит времени (то есть,
для процесса r,
когда p превышает лимит времени (то есть, ![]() -
или
-
или ![]() или
или ![]() ), и
), и ![]() - значение в
- значение в ![]() для процесса r, когда p
вычисляет
для процесса r, когда p
вычисляет ![]() (То есть
(То есть ![]() - или
- или ![]() или
или ![]() ). Точность будет ограничена
разделением суммирования в вычислении решения на суммирование над корректными
процессами (C) и некорректными процессами (B). Для корректных p и q, разность
). Точность будет ограничена
разделением суммирования в вычислении решения на суммирование над корректными
процессами (C) и некорректными процессами (B). Для корректных p и q, разность ![]() ограничена 0, если
ограничена 0, если ![]() , и
, и ![]() если
если ![]() .
.
Первая граница следует из того, что, так как если p и r -
корректные процессы, то ![]() .
Действительно, так как r отвечает на сообщение p <ask>
быстро,
.
Действительно, так как r отвечает на сообщение p <ask>
быстро, ![]() . Точно так же
. Точно так же ![]() для всех корректных r', и
предположение о входе означает, что значение r переживает фильтрацию процессом
p, следовательно Учреждение, несущее основную ответственность
для всех корректных r', и
предположение о входе означает, что значение r переживает фильтрацию процессом
p, следовательно Учреждение, несущее основную ответственность ![]() .
.
Вторая граница справедлива, так как для корректных p и q, ![]() , когда p и q вычисляют свои
решения. Так как добавленные оценки находятся между принятыми значениями,
достаточно рассмотреть максимальное различие между значениями
, когда p и q вычисляют свои
решения. Так как добавленные оценки находятся между принятыми значениями,
достаточно рассмотреть максимальное различие между значениями ![]() и
и ![]() , которые прошли фильтры p и
q соответственно. Имеется по крайней мере N-t процессов
r, для которых
, которые прошли фильтры p и
q соответственно. Имеется по крайней мере N-t процессов
r, для которых ![]() , и по крайней
мере N-t процессов r, для которых
, и по крайней
мере N-t процессов r, для которых ![]() . Это означает, что имеется корректный
r такой, что
. Это означает, что имеется корректный
r такой, что ![]() и
и ![]() ; но так как r корректен,
; но так как r корректен, ![]() , следовательно
, следовательно ![]() .
.
Отсюда следует, что для корректных p и q,
![]() =
=
![]()
= 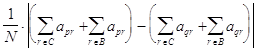
= 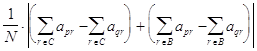
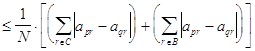
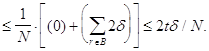
o
Произвольная точность может быть достигнута повторением
алгоритма; после i итераций, точность становится ![]() .
Точность даже лучше, если меньшая доля (чем треть) процессов сбойная; в выводе
точности t можно понимать как фактическое число сбойных процессов. Выходную
точность алгоритма (самую худшую) нельзя улучшить подходящим выбором функции estimator;
действительно, Византийский процесс r может навязать p любое значение
.
Точность даже лучше, если меньшая доля (чем треть) процессов сбойная; в выводе
точности t можно понимать как фактическое число сбойных процессов. Выходную
точность алгоритма (самую худшую) нельзя улучшить подходящим выбором функции estimator;
действительно, Византийский процесс r может навязать p любое значение ![]() , просто посылая p это
значение. Функция может быть выбрана соответственно, чтобы достигнуть хорошей
средней точности, когда известно что-нибудь о наиболее вероятном поведении
сбойных процессов.
, просто посылая p это
значение. Функция может быть выбрана соответственно, чтобы достигнуть хорошей
средней точности, когда известно что-нибудь о наиболее вероятном поведении
сбойных процессов.
Синхронизация Часов. Чтобы синхронизировать часы,
используется алгоритм с быстрой сходимостью, чтобы достигнуть неточного
соглашения по новому значению часов. Предполагается, что часы первоначально ![]() синхронизированы. Алгоритм
должен быть адаптирован, так как
синхронизированы. Алгоритм
должен быть адаптирован, так как
(1) Задержка сообщения точно не известна, так что процесс не может знать точное значение другого процесса; и
(2) При выполнении алгоритма идет время, так что часы не имеют постоянных значения, а увеличиваются со временем.
Чтобы компенсировать неизвестную задержку, процесс добавляет ![]() к получаемым значениям
часов (как в детерминированном протоколе Теоремы 14.12), вводя дополнительное
слагаемое
к получаемым значениям
часов (как в детерминированном протоколе Теоремы 14.12), вводя дополнительное
слагаемое ![]() в выходную точность. Чтобы
представлять полученное значение как значение часов, а не как константу, p
хранит разность полученного значения часов (плюс
в выходную точность. Чтобы
представлять полученное значение как значение часов, а не как константу, p
хранит разность полученного значения часов (плюс ![]() )
и собственного как
)
и собственного как ![]() . Во время t,
приближение часов r процессом p -
. Во время t,
приближение часов r процессом p - ![]() . Измененный алгоритм дан
как Алгоритм 14.7.
. Измененный алгоритм дан
как Алгоритм 14.7.
var ![]() ,
, ![]() ,
, ![]() : real; (*Вход,
адаптация, оценщик V *)
: real; (*Вход,
адаптация, оценщик V *)
![]() ,
,
![]() :
multiset of real;
:
multiset of real;
begin (*фаза сбора входов*)
![]()
forall ![]() do send <ask>
to q
do send <ask>
to q
wait ![]() ; (*Обработать
сообщения <ask> и <val, x>*)
; (*Обработать
сообщения <ask> и <val, x>*)
while ![]() do insert (
do insert (![]() );
);
(*Теперь вычислить приемлемые значения*)
![]()
![]()
while ![]() do insert(
do insert(![]() ,
, ![]() );
);
![]()
![]()
end
После получения <ask> от q:
send<val, ![]() > to q
> to q
После получения <val, С> от q:
if такое сообщение не было получено от q прежде
then ![]()
Алгоритм 14.7 быстрая сходимость часов.
Заметьте, что в Алгоритме 14.7 фильтр имеет более широкую
грань, а именно ![]() , чем в Алгоритме
14.6, где грань
, чем в Алгоритме
14.6, где грань ![]() . Более широкая
грань компенсирует неизвестную задержку сообщения, и порог возникает из
следующего утверждения. Пусть
. Более широкая
грань компенсирует неизвестную задержку сообщения, и порог возникает из
следующего утверждения. Пусть ![]() обозначает
значение, которое p вставил в
обозначает
значение, которое p вставил в ![]() для процесса
r после первой фазы p (сравните со значением
для процесса
r после первой фазы p (сравните со значением ![]() в
предыдущем алгоритме).
в
предыдущем алгоритме).
Утверждение 14.15
Для корректных p, q, и r, после лимита времени p выполняется ![]() .
.
Доказательство. Передача сообщения <val,
C> от q до p осуществляет детерминированный алгоритм чтения часов из
Теоремы 14.12. Когда p получает это сообщение, ![]() ограничено
ограничено
![]() , поэтому
, поэтому ![]() отличается самое большее на
отличается самое большее на
![]() от
от ![]() . Точно так же
. Точно так же ![]() отличается
отличается
[1] - функция Эйлера “фи”; - размер
