

 Реферат: Распределенные алгоритмы
Реферат: Распределенные алгоритмы

Алгоритм 2.3 Логические часы Лампорта
(3) Логические часы Лампорта. Лампорт [Lam78] представил часовую функцию, которая приписывает событию а длину k самой длинной последовательности (е1, …, еk) событий, удовлетворяющей
е1 í е2 í … íеk = a
В самом деле, если а í b, эта последовательность может быть расширена, чтобы показать, что QL(a) < QL(b). Значение QL может быть вычислено для каждого события распределенным алгоритмом, базируясь на следующих отношениях.
(а) Если а есть внутреннее событие или событие посылки, и а’ – предыдущее событие в том же процессе, то QL(a) = QL(a’) + 1.
(b) Если а – событие получение, а’ – предыдущее событие в том же процессе, и b –событие посылки, соответствующее а, то QL(a) = max(QL(a’), QL(b)) + 1.
В обоих случаях QL(a’) предполагается нулевым, если а – первое событие в процессе.
Чтобы вычислить значения часов распределенным алгоритмом, значение часов последнего события процесса р сохраняется в переменной qр (инициализируемой в 0). Для того, чтобы вычислить значение часов события получения, каждое сообщение m содержит значение часов qm события е, при котором оно было послано. Логически часы Лампорта даны как алгоритм 2.3. Для события е в процессе р, QL(е) есть значение qр сразу же после появления е, т.е. в момент, когда происходит изменение состояния процесса р. Оставлена для упражнения демонстрация того, что с этим определением QL является часами.
Не указывается при каких условиях сообщение должно быть послано или как меняется состояние процесса. Часы –это дополнительный механизм, который может быть добавлен к любому распределенному алгоритму, чтобы упорядочивать события.
(4) Векторные часы. Для некоторых целей полезно иметь часы, который выражают не только каузальный порядок (как требуется по определению 2.25), но также и конкуренцию. Конкуренция выражается часами, если конкурентные события помечаются несравнимыми значениями часов, то есть, следствие в определении 2.25 заменяется на эквиваленцию, давая
a í b Û Q(а) < Q(b). (2.1)
Существование конкурирующих событий подразумевает, что область таких часов (множество Х) – не-полностью-упорядоченное множество.
В векторных часах Маттерна [Mat89b] X = NN, т.е. Qv(a) есть вектор длины N. Вектора длины n естественным образом упорядочены векторным порядком, определенным следующим образом:
(а1, …, аn) £v (b1, …, bn) Û "i (1 £ i £ n) : ai £ bi. (2.2)
(Векторный порядок отличается от лексикографического порядка, определенного в упражнении 2.5, последний порядок абсолютен). Часы, определяемые Qv(a) = (а1, …, аN), аi – это число событий е в процессе р1, для которого е í а. Как и часы Лампорта, эта функция может быть вычислена распределенным алгоритмом.
Чаррон-Бост [CB89] показал, что невозможно использовать более короткие векторы (с векторным порядком как в (2.2)). Если события произвольного исполнения из N процессов отображаются на вектора длины n таких, что (2.1) удовлетворяется, то n ³ N.
2.4 Дополнительные допущения, сложность
Определений сделанных до сих пор в этой главе достаточно, чтобы развивать оставшиеся главы. Определенная модель служит как основа для представления и проверки алгоритмов, так и для доказательств невозможности для решения распределенных проблем. В различных главах используются дополнительные допущения и нотация, если требуется. Этот раздел обсуждает некоторую терминологию, которая также общеупотребительна в литературе по распределенным алгоритмам. До сих пор, мы моделировали коммуникационную подсистему распределенной системы набором сообщений, находящихся в данный момент в процессе передачи. Далее, мы будем предполагать, что каждое сообщение может передаваться только одним процессом, называемым назначением сообщения. В общем, не обязательно чтобы каждый процесс мог посылать сообщения каждому другому процессу. Вместо этого, для каждого процесса определено подмножество других процессов (называемых соседями процесса), к которым он может посылать сообщения. Если процесс р может посылать сообщения процессу q, говорят, что существует канал от р до q. Если не утверждается обратное, предполагается, что каналы двунаправленные, то есть, тот же канал позволяет посылать q сообщения процессу p. Канал, который осуществляет только однонаправленный трафик от р к q, называется однонаправленным (или направленным) каналом от р до q.
Набор процессов и коммуникационная подсистема также упоминается как сеть. Структура коммуникационной подсистемы часто представляется как граф G = (V, E), в котором вершины – это процессы, и ребра между двумя процессами существуют, если и только если канал существует канал между двумя процессами. Система с однонапрвленными каналами может подобным образом представлена направленными графом. Граф распределенной системы также называется ее сетевой топологией.
Представление графом позволяет нам говорить о коммуникационной системе в терминах теории графов. См. дополнение Б для представления об этой терминологии. Так как сетевая топология происходит от основного влияния на существование, внешний вид, и сложность распределенных алгоритмов для многих проблем, мы включаем ниже краткое обсуждение некоторых повсеместно используемых здесь топологий. См. дополнение Б для дополнительных деталей. На протяжении этой книги, если не утверждается обратное, предполагается, что топология связана, то есть, существует путь между двумя вершинами.
(1) Кольца. N-вершинное кольцо – граф на вершинах от v0 до vN-1 c ребрами v0vN-1 (индексы – по модулю N). Кольца часто используются для распределенного управления вычислениями, потому что они просты. Также, некоторые физические сети, такие как Token Rings [Tan88, раздел 3.4], распределяют узлы в кольцо.
(2) Деревья. Дерево на N вершинах – это связанный граф с N –1 ребрами, он не содержит циклов. Деревья используются в распределенных вычислениях, потому что они позволяют проводить вычисление при низкой цене коммуникаций, и более того, каждый связанный граф содержит дерево, как подсеть охвата.
(3) Звезды. Звезда на N вершинах имеет одну специальную вершину (центр) и N-1 ребер, соединяющих каждую из N-1 вершин с центром. Звезды используются в централизованных вычислениях, где один процесс действует как контроллер и все другие процессы сообщаются только с этим специальным процессом. Недостатки звездной топологии это узкое место, каким может стать центр и уязвимость такой системы из-за повреждений в центре.
(4) Клики. Клика – это сеть, в которой ребро существует между любыми двумя вершинами.
(5) Гиперкубы. Гиперкуб – это граф HCN = (V, E) на N = 2n вершинах. Здесь V – множество битовых строк длины n:
V = {(b0 , ..., bn-1) : bi Î {0, 1}},
и ребро существует между двумя вершинами b и с, тогда и только тогда, когда битовые строки b и с различаются точно на один бит. Имя гиперкуба относится к графическому представлению сети как n-размерного куба, углы которого – вершины.
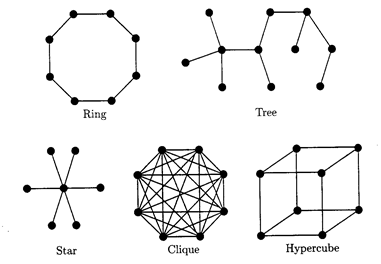
Рис. 2.4 Примеры часто используемых топологий
Примеры каждой из этих сетей приведены на рис 2.4. Топология может быть статической или динамической. Статическая топология означает, что топология остается фиксированной в течение распределенного вычисления. Динамическая топология означает, что каналы (иногда даже процессы) могут быть добавлены или удалены из системы в течение вычисления. Эти изменения в топологии могут быть также смоделированы переходами конфигураций, а именно, если состояния процесса отражают множество соседей процесса (см. главу 4).
Модель (как описана в подразделе 2.1.2) может быть усовершенствована при помощи представления содержимого каждого канала раздельно в конфигурации, то есть, замены множества М на набор множеств Мрq для каждого (однонаправленного) канала рq. Так как мы постулировали, что каждое сообщение неявно определяет свое назначение, то эта модификация не изменяет важных свойств модели. Далее обсуждаются некоторые общие допущения относительно соотношения событий приема и посылки.
(1) Надежность. Говорят, что канал надежен, когда каждое сообщение, которое посылается в канал принимается точно один раз (обеспечив назначению возможность получить сообщение). Если не утверждается обратное, всегда предполагается в этой книге, что каналы надежны. Это допущение фактически добавляет (слабое) условие справедливости. В самом деле, после того как сообщение послано, получение этого сообщения (в приемлемом для назначения состоянии) применимо.
Канал, который ненадежен, может проявлять коммуникационные сбои, которые могут быть нескольких типов, например, утеря, искажение, дублирование, порождение. Эти сбои могут быть представлены переходами в модели определения 2.6, но эти переходы не соответствуют изменениям состояния процесса.
Утеря сообщения имеет место, когда сообщение посылается, но никогда не принимается. Это может быть смоделирована переходом, который удаляет сообщение из М. Искажение сообщение встречается, когда полученное сообщение отличается от посланного сообщения. Это может быть смоделировано переходом, который меняет одно сообщение из М. Дублирование сообщения появляется, если сообщение принимается более часто, чем оно посылалось. Это может быть смоделировано переходом, который копирует сообщение из М. Порождение сообщения, встречается, когда сообщение получено, но никогда не было послано, это моделируется переходом, который вставляет сообщение в М.
Страницы: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105
