

 Шпаргалка: Лекции по количественной оценке информации
Шпаргалка: Лекции по количественной оценке информации
Однако эту цифру необходимо округлить до ближайшего целого числа, так как длина кода не может быть выражена дробным числом. Округление, естественно, производится в большую сторону. В общем случае, избыточность от округления
![]()
где ![]() —
округленное до ближайшего целого числа значение
—
округленное до ближайшего целого числа значение ![]() .
Для нашего примера
.
Для нашего примера
![]()
Избыточность
— не всегда нежелательное явление. Для повышения помехоустойчивости кодов
избыточность необходима и ее вводят искусственно в виде добавочных ![]()
![]() символов
(см. тему 6). Если в коде всего п разрядов и
символов
(см. тему 6). Если в коде всего п разрядов и ![]() из
них несут информационную нагрузку, то
из
них несут информационную нагрузку, то ![]() =
=![]()
![]() характеризует абсолютную корректирующую избыточность, а величина
характеризует абсолютную корректирующую избыточность, а величина ![]() характеризует относительную
корректирующую избыточность.
характеризует относительную
корректирующую избыточность.
Информационная избыточность - обычно явление естественное, заложена она в первичном алфавите. Корректирующая избыточность - явление искусственное, заложена она в кодах, представленных во вторичном алфавите.
Наиболее эффективным способом уменьшения избыточности сообщения является построение оптимальных кодов.
Оптимальные коды[5] - коды с практически нулевой избыточностью. Оптимальные коды имеют минимальную среднюю длину кодовых слов - L. Верхняя и нижняя границы L определяются из неравенства
![]() (49)
(49)
где Н - энтропия первичного алфавита, т - число качественных признаков вторичного алфавита.
В случае поблочного кодирования, где каждый из блоков
состоит из М независимых букв ![]() ,
минимальная средняя длина кодового блока лежит в пределах
,
минимальная средняя длина кодового блока лежит в пределах
![]() (50)
(50)
Общее выражение среднего числа элементарных символов на букву сообщения при блочном кодировании
![]() (51)
(51)
С точки зрения информационной нагрузки на символ сообщения поблочное кодирование всегда выгоднее, чем побуквенное.
Суть блочного кодирования можно уяснить на примере представления десятичных цифр в двоичном коде. Так, при передаче цифры 9 в двоичном коде необходимо затратить 4 символа, т. е. 1001. Для передачи цифры 99 при побуквенном кодировании - 8, при поблочном - 7, так как 7 двоичных знаков достаточно для передачи любой цифры от 0 до 123; при передаче цифры 999 соотношение будет 12 - 10, при передаче цифры 9999 соотношение будет 16 - 13 и т. д. В общем случае «выгода» блочного кодирования получается и за счет того, что в блоках происходит выравнивание вероятностей отдельных символов, что ведет к повышению информационной нагрузки на символ.
При построении оптимальных кодов наибольшее распространение нашли методики Шеннона—Фано и Хаффмена.
Согласно методике Шеннона - Фано построение оптимального кода ансамбля из сообщений сводится к следующему:
1-й шаг. Множество из сообщений располагается в порядке убывания вероятностей.
2-й шаг. Первоначальный ансамбль кодируемых сигналов разбивается на две группы таким образом, чтобы суммарные вероятности сообщений обеих групп были по возможности равны. Если равной вероятности в подгруппах нельзя достичь, то их делят так, чтобы в верхней части (верхней подгруппе) оставались символы, суммарная вероятность которых меньше суммарной вероятности символов в нижней части (в нижней подгруппе).
3-й шаг. Первой группе присваивается символ 0, второй группе символ 1.
4-й шаг. Каждую из образованных подгрупп делят на две части таким образом, чтобы суммарные вероятности вновь образованных подгрупп были по возможности равны.
5-й шаг. Первым группам каждой из подгрупп вновь присваивается 0, а вторым - 1. Таким образом, мы получаем вторые цифры кода. Затем каждая из четырех групп вновь делится на равные (с точки зрения суммарной вероятности) части до тех пор, пока в каждой из подгрупп не останется по одной букве.
Согласно методике Хаффмена, для построения
оптимального кода N символы первичного алфавита выписываются в порядке
убывания вероятностей. Последние ![]() символов,
где
символов,
где ![]() [6]
и
[6]
и ![]() - целое число, объединяют в
некоторый новый символ с вероятностью, равной сумме вероятностей объединенных
символов Последние символы с учетом образованного символа вновь объединяют,
получают новый, вспомогательный символ, опять выписывают символы в порядке
убывания вероятностей с учетом вспомогательного символа и т. д. до тех пор,
пока сумма вероятностей т оставшихся символов после
- целое число, объединяют в
некоторый новый символ с вероятностью, равной сумме вероятностей объединенных
символов Последние символы с учетом образованного символа вновь объединяют,
получают новый, вспомогательный символ, опять выписывают символы в порядке
убывания вероятностей с учетом вспомогательного символа и т. д. до тех пор,
пока сумма вероятностей т оставшихся символов после ![]() -го выписывания в порядке
убывания вероятностей не даст в сумме вероятность, равную 1. На практике
обычно, не производят многократного выписывания вероятностей символов с учетом
вероятности вспомогательного символа, а обходятся элементарными геометрическими
построениями, суть которых сводится к тому, что символы кодируемого алфавита попарно
объединяются в новые символы, начиная с символов, имеющих наименьшую
вероятность. Затем с учетом вновь образованных символов, которым присваивается
значение суммарной вероятности двух предыдущих, строят кодовое дерево, в
вершине которого стоит символ с вероятностью 1. При этом отпадает необходимость
в упорядочивании символов кодируемого алфавита в порядке убывания вероятностей.
-го выписывания в порядке
убывания вероятностей не даст в сумме вероятность, равную 1. На практике
обычно, не производят многократного выписывания вероятностей символов с учетом
вероятности вспомогательного символа, а обходятся элементарными геометрическими
построениями, суть которых сводится к тому, что символы кодируемого алфавита попарно
объединяются в новые символы, начиная с символов, имеющих наименьшую
вероятность. Затем с учетом вновь образованных символов, которым присваивается
значение суммарной вероятности двух предыдущих, строят кодовое дерево, в
вершине которого стоит символ с вероятностью 1. При этом отпадает необходимость
в упорядочивании символов кодируемого алфавита в порядке убывания вероятностей.
Построенные по указанным выше (либо подобным) методикам коды с неравномерным распределением символов, имеющие минимальную среднюю длину кодового слова, называют оптимальным, неравномерным, кодами (ОНК). Равномерные коды могут быть оптимальными только для передачи сообщений с равновероятным распределением символов первичного алфавита, при этом число символов первичного алфавита должно быть равно целой степени числа, равного количеству качественных признаков вторичного алфавита, а в случае двоичных кодов - целой степени двух.
Максимально эффективными будут те ОНК, у которых
![]()
Для двоичных кодов
![]() (52)
(52)
так как log22 = 1. Очевидно, что равенство (52) удовлетворяется при условии, что длина кода во вторичном алфавите
![]()
Величина
![]() точно равна Н, если
точно равна Н, если ![]() , где п - любое
целое число. Если п не является целым числом для всех значений букв
первичного алфавита, то
, где п - любое
целое число. Если п не является целым числом для всех значений букв
первичного алфавита, то ![]() и,
согласно основной теореме кодирования[7],
средняя длина кодового слова приближается к энтропии источника сообщений по
мере укрупнения кодируемых блоков.
и,
согласно основной теореме кодирования[7],
средняя длина кодового слова приближается к энтропии источника сообщений по
мере укрупнения кодируемых блоков.
Эффективность ОНК. оценивают при помощи коэффициента статистического сжатия:
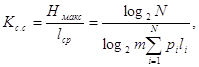 (53)
(53)
который характеризует уменьшение количества двоичных знаков на символ сообщения при применении ОНК по сравнению с применением методов нестатистического кодирования и коэффициента относительной эффективности
![]() (54)
(54)
который показывает, насколько используется статистическая избыточность передаваемого сообщения.
Для наиболее общего случая неравновероятных и взаимонезависимых символов
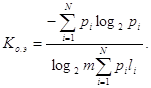
Для случая неравновероятных и взаимозависимых символов
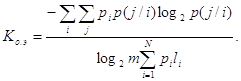
ТЕМА 6. ОБНАРУЖЕНИЕ И ИСПРАВЛЕНИЕ ОШИБОК В СООБЩЕНИЯХ
Понятие об идее коррекции ошибок
Для того чтобы в принятом сообщении можно было обнаружить ошибку это сообщение должно обладать некоторой избыточной информацией, позволяющей отличить ошибочный код от правильного Например, если переданное сообщение состоит из трех абсолютно одинаковых частей, то в принятом сообщении отделение правильных символов от ошибочных может быть осуществлено по результатам накопления посылок одного вида, например 0 или 1. Для двоичных кодов этот метод можно проиллюстрировать следующим примером:
10110 - переданная кодовая комбинация;
10010 - 1-я принятая комбинация;
10100 - -я принятая комбинация;
00110 - 3-я принятая комбинация;
10110 - накопленная комбинация.
Страницы: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
