

 Реферат: Классификация сейсмических сигналов на основе нейросетевых технологий
Реферат: Классификация сейсмических сигналов на основе нейросетевых технологий
При обучении сети мы действуем совершенно аналогично. Пусть у нас имеется некоторая база данных, содержащая примеры из разных классов, которые необходимо научиться распознавать (набор рукописных изображений букв). Предъявляя изображение буквы "А" на вход сети, мы получаем от нее некоторый ответ, не обязательно верный. Нам известен и верный (желаемый) ответ - в данном случае нам хотелось бы, чтобы на выходе с меткой "А" уровень сигнала был максимален. Обычно в качестве желаемого выхода в задаче классификации берут набор (1,0,0,...), где 1 стоит на выходе с меткой "А", а 0 - на всех остальных выходах. Вычисляя разность между желаемым ответом и реальным ответом сети, мы получаем 33 числа - вектор ошибки. Далее применяя различные алгоритмы по вектору ошибки вычисляем требуемые поправки для весов сети. Одну и ту же букву (а также различные изображения одной и той же буквы) мы можем предъявлять сети много раз. В этом смысле обучение скорее напоминает повторение упражнений в спорте - тренировку.
Оказывается, что после многократного предъявления примеров веса сети стабилизируются, причем сеть дает правильные ответы на все (или почти все) примеры из базы данных. В таком случае говорят, что "сеть выучила все примеры", " сеть обучена", или "сеть натренирована". В программных реализациях можно видеть, что в процессе обучения величина ошибки (сумма квадратов ошибок по всем выходам) постепенно уменьшается. Когда величина ошибки достигает нуля или приемлемого малого уровня, тренировку останавливают, а полученную сеть считают натренированной и готовой к применению на новых данных. Схематично процесс обучения представлен на рис 1.5.
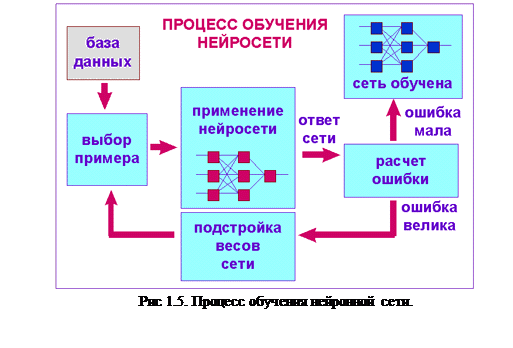
Важно отметить, что вся информация, которую сеть имеет о задаче, содержится в наборе примеров. Поэтому качество обучения сети напрямую зависит от количества примеров в обучающей выборке, а также от того, насколько полно эти примеры описывают данную задачу. Так, например, бессмысленно использовать сеть для распознавания буквы “A”, если в обучающей выборке она не была представлена. Считается, что для полноценной тренировки требуется хотя бы несколько десятков (а лучше сотен) примеров. Повторим еще раз, что обучение сети - сложный и наукоемкий процесс. Алгоритмы обучения имеют различные параметры и настройки, для управления которыми требуется понимание их влияния.
Применение нейросети.
После того, как сеть обучена, ее можно применять ее для решения поставленной задачи (рис 1.4). Важнейшая особенность человеческого мозга состоит в том, что, однажды обучившись определенному процессу, он может верно действовать и в тех ситуациях, в которых он не бывал в процессе обучения. Например, можно читать почти любой почерк, даже если видим его первый раз в жизни. Так же и нейросеть, грамотным образом обученная, может с большой вероятностью правильно реагировать на новые, не предъявленные ей ранее данные. Например, мы можем нарисовать букву "А" другим почерком, а затем предложить нашей сети классифицировать новое изображение. Веса обученной сети хранят достаточно много информации о сходстве и различиях букв, поэтому можно рассчитывать на правильный ответ и для нового варианта изображения
Примеры практического применения нейронных сетей.
В качестве примеров рассмотрим наиболее известные классы задач, для решения которых в настоящее время широко применяются нейросетевые технологии.
Прогнозирование.
 Прогноз будущих значений переменной, зависящей от времени, на
основе предыдущих значений ее и/или других переменных. В финансовой области,
это ,например, прогнозирование курса акций на 1 день вперед,
Прогноз будущих значений переменной, зависящей от времени, на
основе предыдущих значений ее и/или других переменных. В финансовой области,
это ,например, прогнозирование курса акций на 1 день вперед,
или прогнозирование изменения курса валют на определен
ный период времени и т.д.. (рис 1.6)
Распознавание или классификация.
Определение, к какому из заранее известных классов принадлежит тестируемый объект. Следует отметить, что задачи классификации очень плохо алгоритмизируются. Если в случае распознавания букв верный ответ очевиден для нас заранее, то в более сложных практических задачах обученная нейросеть выступает как эксперт, обладающий большим опытом и способный дать ответ на трудный вопрос.
 Примером такой задачи служит
Примером такой задачи служит
медицинская диагностика, где сеть может
учитывать большое количество числовых
параметров (энцефалограмма, давление, вес и т.д.).
Конечно, "мнение" сети в этом случае нельзя
считать окончательным.
 Классификация предприятий по степени их перспективности (рис
1.8) - это уже привычный способ использования нейросетей в практике крупных
компаний. При этом сеть также использует множество
Классификация предприятий по степени их перспективности (рис
1.8) - это уже привычный способ использования нейросетей в практике крупных
компаний. При этом сеть также использует множество
экономических показателей,
сложным образом связанных
между собой.
Кластеризацию и поиск закономерностей.
Помимо задач классификации, нейросети широко используются для поиска зависимостей в данных и кластеризации.
Например, нейросеть на основе методики МГУА (метод группового учета аргументов) позволяет на основе обучающей выборки построить зависимость одного параметра от других в виде полинома (рис. 1.9). Такая сеть может не только мгновенно выучить таблицу умножения, но и найти сложные скрытые зависимости в данных (например, финансовых), которые не обнаруживаются стандартными статистическими методами.
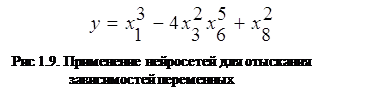
Кластеризация - это разбиение набора примеров на несколько компактных областей (кластеров), причем число кластеров заранее неизвестно (рис. 1.10). Кластеризация позволяет представить неоднородные данные в более наглядном виде и использовать далее для исследования каждого кластера различные методы. Например, таким образом можно быстро выявить фальсифицированные страховые случаи или недобросовестные предприятия.
Несмотря на большие возможности, существует ряд недостатков, которые все же ограничивают применение нейросетевых технологий. Во-первых, нейронные сети позволяют найти только субоптимальное решение, и соответственно они неприменимы для задач, в которых требуется высокая точность. Функционируя по принципу черного ящика, они также неприменимы в случае, когда необходимо объяснить причину принятия решения. Обученная нейросеть выдает ответ за доли секунд, однако относительно высокая вычислительная стоимость процесса обучения как по времени, так и по объему занимаемой памяти также существенно ограничивает возможности их использования. И все же класс задач, для решения которых эти ограничения не критичны, достаточно широк.
2. Постановка задачи классификации сейсмических сигналов.
Международная система мониторинга (МСМ), сформировавшаяся в мире за последние десятилетия, предназначена для наблюдения за сейсмически активными регионами. Основная часть информации фиксируется на одиночных сейсмических станциях. Дальнейшая обработка этой информации позволяет оценить различные физические параметры, характеризующие записанное событие. Соответственно чем информативнее записанный сигнал, тем больше всевозможных параметров можно определить и точнее. Относительно недавно для наблюдения стали использовать группы сейсмических станций. Наиболее широкое применение получили малоапертурные группы с диаметром приблизительно 3 км. за счет того, что в этом случае можно пренебречь искажениями сигнала, возникающими из-за неоднородности земной поверхности.
Причина использования сейсмических групп также заключается в том, что при таком методе наблюдения можно применять специальные алгоритмы комплексной обработки регистрируемой многоканальной сейсмограммы, которые обеспечивают лучшее качество оценки параметров записанной информации, в сравнении с одиночными сейсмическими станциями.
Одна из многочисленных задач, возникающих при региональном мониторинге, это задача идентификации типа сейсмического источника или задача классификации сейсмических сигналов. Она состоит в том, чтобы по сейсмограмме определить причину возникновения зафиксированного события, т.е. различить взрыв и землетрясение. Ее решение предусматривает разработку определенного метода (решающего правила), который с определенной вероятностью мог бы отнести записанное событие к одному из двух классов. На рис.2.1 представлена схема постановки задачи.

Для решения этой задачи в настоящее время применяются различные аналитические методы из теории статистического анализа, позволяющие с высокой вероятностью правильно классифицировать данные. Как правило, для конкретного региона существует своя база данных записанных событий. Она включает в себя пример сейсмограмм характеризующих как землетрясения, так и взрывы произошедшие в этом регионе с момента начала наблюдения. Все существующие методы идентификации используют эту базу данных в качестве обучающего множества, тем самым, улавливая тонкие различия характерные для данного региона, методы, настраивают определенным образом свои параметры и в итоге учатся классифицировать все обучающее множество на принадлежность к одному из двух классов.
Один из наиболее точных методов основан на выделении дискриминантных признаков из сейсмограмм и последующей классификации векторов признаков с помощью статистических решающих правил. Размерность таких векторов соответствует количеству признаков, используемых для идентификации и, как правило, не превышает нескольких десятков.
Страницы: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14
