· Generalized Additive Models (GAM) -
Обобщенные аддитивная модели (GAM). Набор методов, разработанных и
популяризованных Hastie и Tibshirani (1990); более детальное рассмотрение этих
методов вы также может найти в работах Schimek (2000).
· General Classification and Regression
Trees (GTrees) - Обобщенные классификационные и регрессионные деревья (GTrees).
Модуль является полной реализацией методов разработанных Breiman, Friedman,
Olshen, и Stone (1984). Кроме этого модуль содержит разного рода доработки и
дополнения такие как, оптимизации алгоритмов для больших объемов данных и т.д.
Модуль является набором методов обобщенной классификации и регрессионных
деревьев.
· General CHAID (Chi-square Automatic
Interaction Detection) Models - Обобщенные CHAID модели (Хи-квадрат
автоматическое обнаружение взаимодействия). Подобно предыдущему элементу данный
модуль является оптимизацией данной математической модели для больших объемов
данных.
data miner statistica
регрессия кластеризация
· Interactive Classification and
Regression Trees - Интерактивная классификация и регрессионные деревья. В
дополнение к модулям автоматического построения разного рода деревьев, STATISTICA
Data Miner также включает средства для формирования таких деревьев в
интерактивном режиме.
· Boosted Trees - Расширяемые простые
деревья. Последние исследование аналитических алгоритмов показывают, что для
некоторых задач построения "сложных" оценок, прогнозов и
классификаций, использование последовательно увеличиваемых простых деревьев
дает более точные результаты чем нейронные сети или сложные цельные деревья.
Данный модуль реализует алгоритм построения простых увеличиваемых (расширяемых)
деревьев.
· Multivariate Adaptive Regression
Splines (Mar Splines) - Многомерные адаптивные регрессионные сплайны (Mar
Splines). Данный модуль основан на реализации методики предложенной Friedman
(1991; Multivariate Adaptive Regression Splines, Annals of Statistics, 19,
1-141); в STATISTICA Data Miner расширены опции MARSPLINES для того, чтобы
приспособить задачи регрессии и классификации к непрерывными и категориальным
предикторам.
· Goodness of Fit Computations -
Критерии согласия. Данный модуль производит вычисления различных статистических
критериев согласия как для непрерывных переменных, так и для категориальных.
· Rapid Deployment of Predictive Models
- Быстрые прогнозирующие модели (для большого числа наблюдаемых значений).
Модуль позволяет строить за короткое время классификационные и прогнозирующие
модели для большого объема данных. Полученные результаты могут быть
непосредственно сохранены во внешней базе данных.
Пример работы в DataMining
Создание отчетов и итогов
Открываем базу данных:
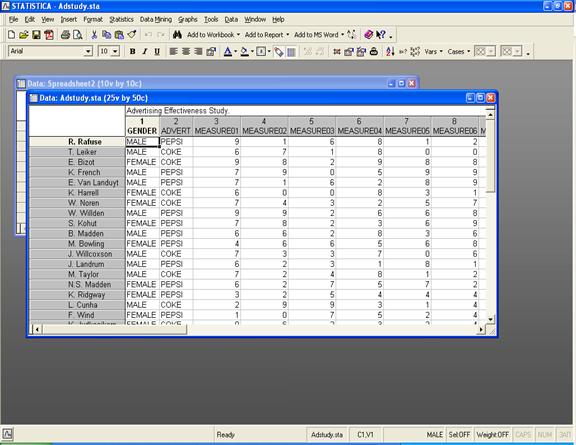
Таблица содержит имена менеджеров в
различных ресторанных сетях. Первая колонка – пол менеджера, вторая – что
поставляется от вашего ресторана менеджерам, колонки с 3 по 26 – информация о
количестве закупок по 23 месяцам сделанных у вашей компании.
Необходимо определить какой из менеджеров
купил больше всего продукции, поделенной по типам продукции.
Выбираем среду
работы в DataMining ->Workspaces->All Procedures.
Выбираем данные (базу данных) для работы:
Выбираем переменные:
Далее необходимо убрать все нули без
потери данных для вычисления среднего числа:
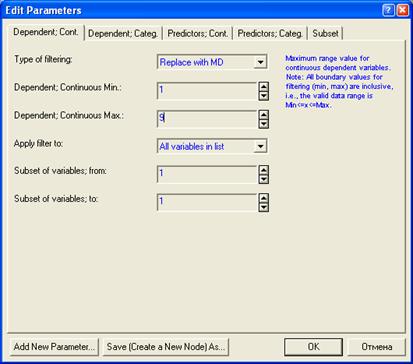
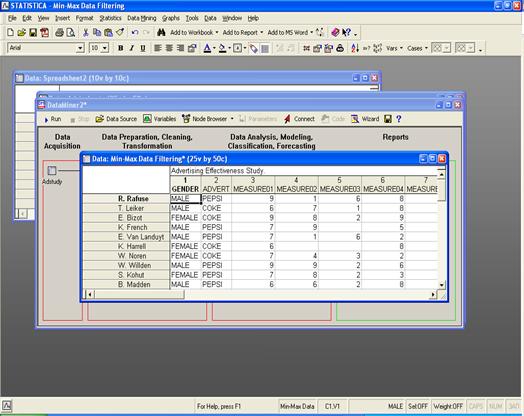
Далее определяем параметры фильтрации:
После запуска проекта на выполнение:
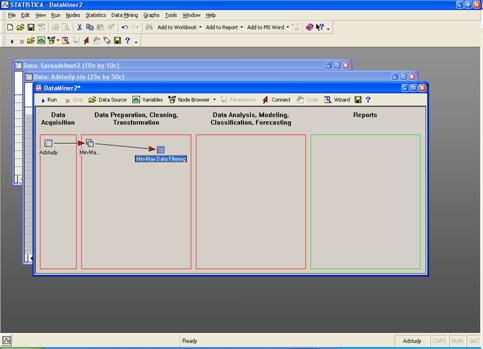
Все нулевые значения убраны:
Далее посчитаем среднее число поставок за
последние 3 и 6 месяцев:
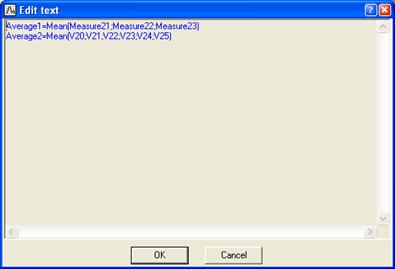
Запускаем проект на выполнение.
Результат:
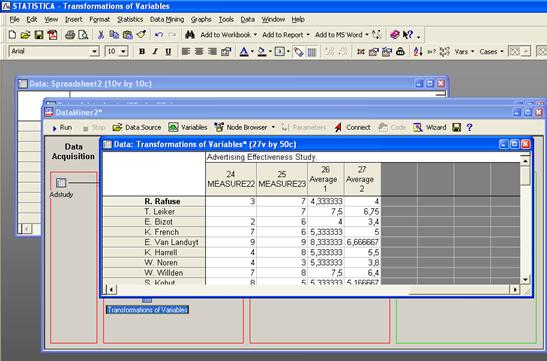
Сортировка информации
Отсортируем информацию по двум переменным,
которые мы создали.
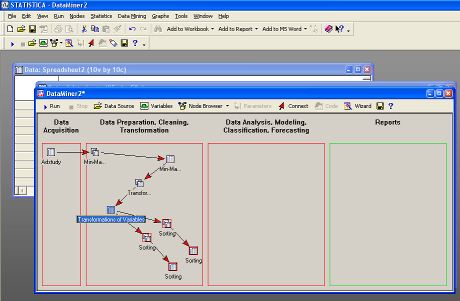
Для первой сортировки:
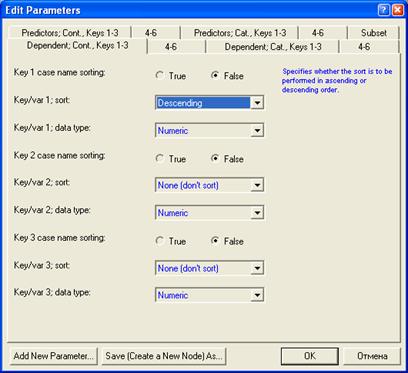
Для второй сортировки:
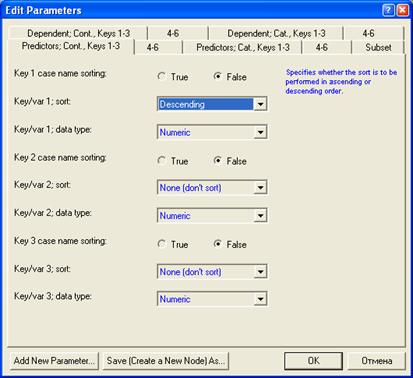
Запускаем проект на выполнение:
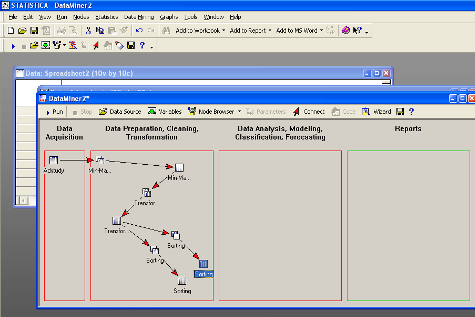
Результат первой сортировки:
Построение графика:
Далее выбираем вид процедур:
Запускаем проект на выполнение:
Результаты:
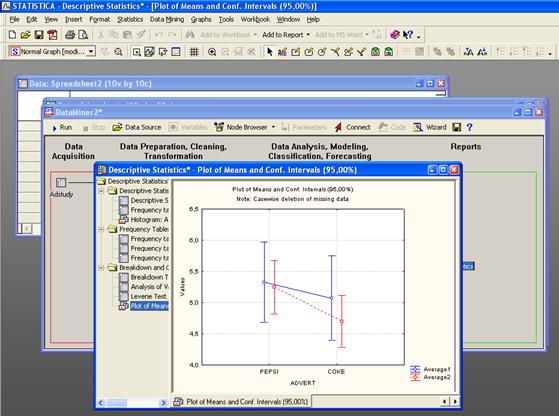
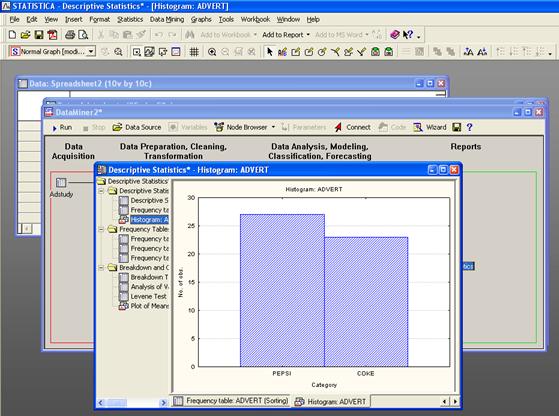
Анализ цен жилищных участков
Выбираем среду работы в DataMining ->Workspaces->All Procedures.
Выбираем данные (базу данных) для работы:
В следующем примере анализируются данные о
жилищном строительстве в Бостоне. Цена участка под застройку классифицируется
как Низкая - Low, Средняя - Medium или Высокая - High в зависимости от значения
зависимой переменной Price. Имеется один категориальный предиктор - Cat1 и 12
порядковых предикторов - Ord1-Ord12. Весь набор данных, состоящий из 1012
наблюдений, содержится в файле примеров Boston2.sta.
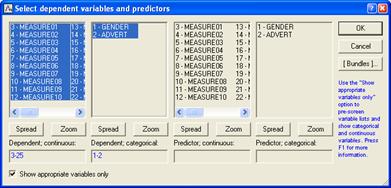
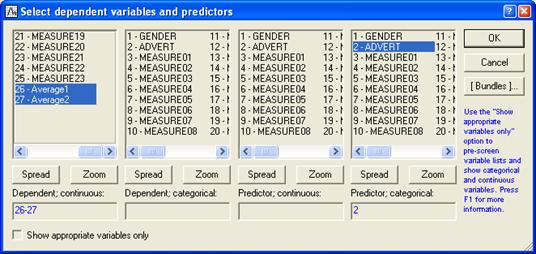
Далее выбираем переменные для анализа.
STATISTICA различает категориальные и непрерывные переменные, а также зависимые
и предикторы (независимые переменные). Категориальные переменные – те, которые
содержат информацию о некотором дискретном количестве или характеристике,
описывающей наблюдения в файле данных (например, Пол: Мужской, Женский);
непрерывные переменные измерены в некотором непрерывном масштабе (например,
Высота, Вес, Стоимость). Зависимые переменные – те, которые мы хотим
предсказать; их также иногда называют переменными результата; предикторы
(независимые) переменные – те, что мы хотим использовать для предсказания или
классификации (категориальных исходящих).
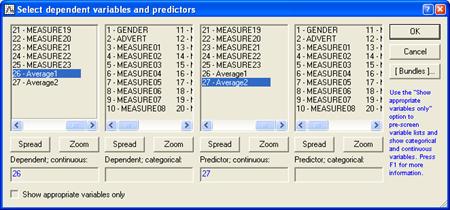
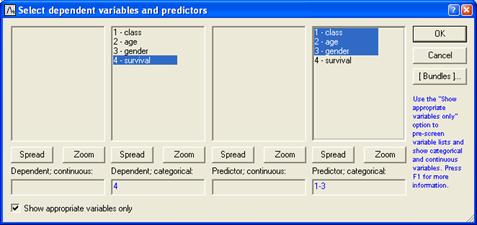
После выбора файла появится окно диалога
"Выберите зависимые переменные и предикторы"
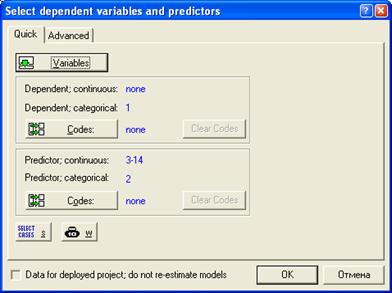
Выбранные переменные для анализа:
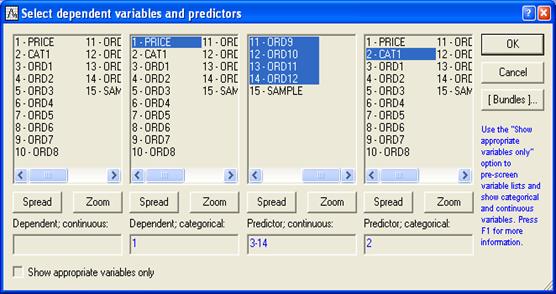
После нажатия кнопки ОК данные заносятся в
рабочее пространство.
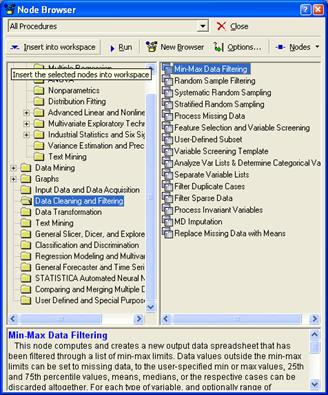
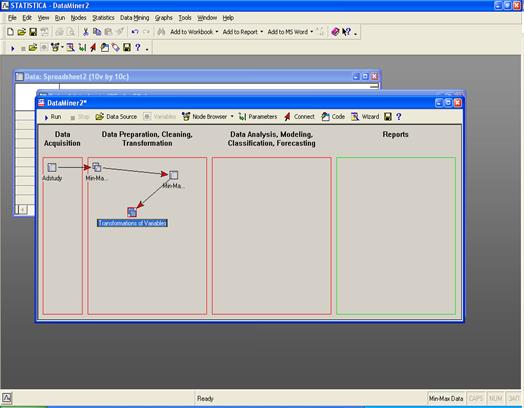
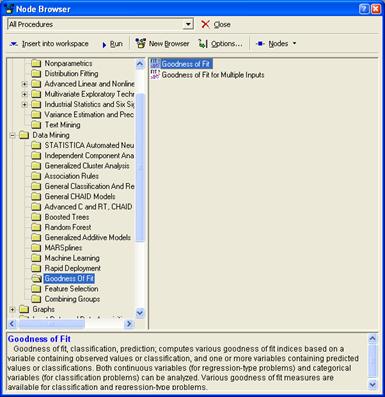
Запускаем диспетчер узлов.
Далее открываем окно для выбора вида
анализа или задания преобразования данных:
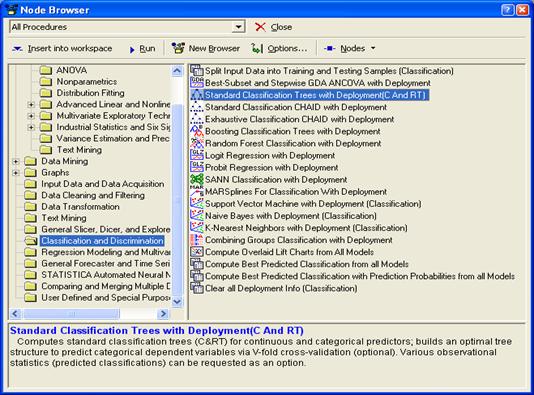
А также выбираем ещё такую процедуру:
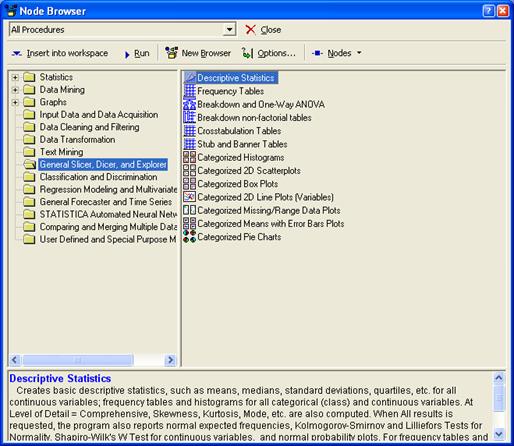
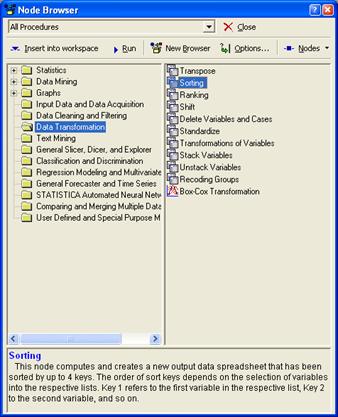
Диспетчер узлов включает в себя все
доступные процедуры для добычи данных. Всего доступно около 260 методов
фильтрации и очистки данных, методов анализа. По умолчанию, процедуры помещены
в папки и отсортированы в соответствии с типом анализа, который они выполняют.
Однако пользователь имеет возможность создать собственную конфигурацию
сортировки методов.
Для того чтобы выбрать необходимый анализ,
необходимо выделить его на правой панели и нажать кнопку "вставить".
В нижней части диалога дается описание выбираемых методов.
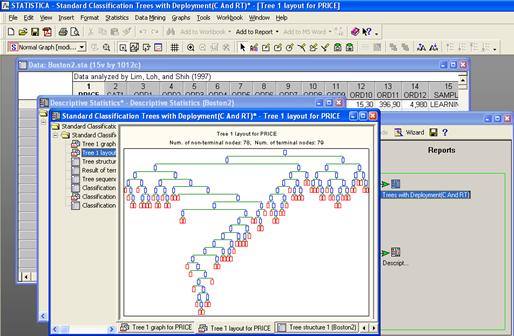
Выберем, для примера, Descriptive
Statistics и Standard Classification Trees with Deployment (C And RT) . Окно
Data Miner выглядит следующим образом.
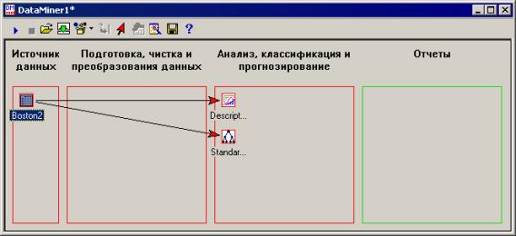
Источник данных в рабочей области Data
Miner автоматически будет соединен с узлами выбранных анализов. Операции
создания/удаления связей можно производить и вручную.
Запускаем на выполнение проект “Run”.
Все узлы, соединенные с источниками данных
активными стрелками, будут проведены:
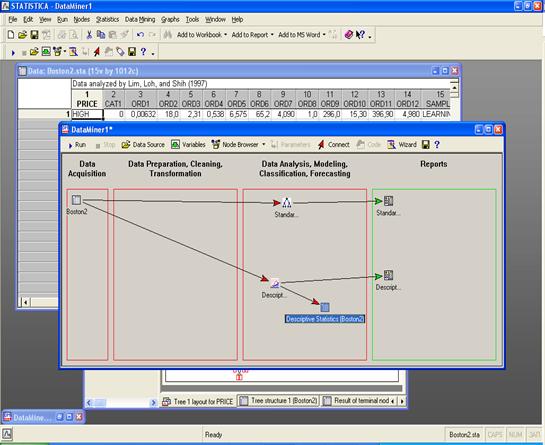
Далее можно просмотреть результаты (в
столбце отчетов). Подробные отчеты создаются по умолчанию для каждого вида
анализа. Для рабочих книг результатов доступна полная функциональность системы
STATISTICA.
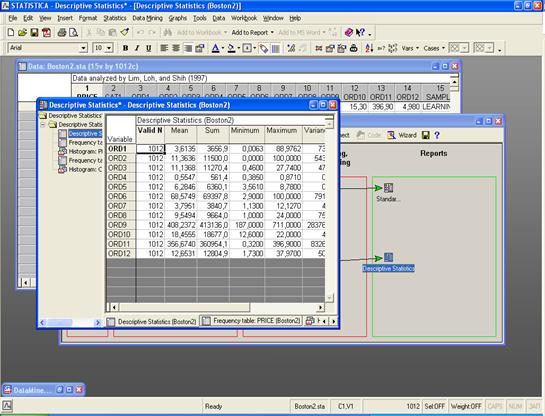
Кроме того, в диспетчере узлов STATISTICA
Data Miner содержатся разнообразные процедуры для классификации и
Дискриминантного анализа, Регрессионных моделей и Многомерного анализа, а также
Обобщенные временные ряды и прогнозирование. Все эти инструменты можно
использовать для проведения сложного анализа в автоматическом режиме, а также
для оценивания качества модели.
Анализ предикторов выживания
Данный пример базируется на данных о
пассажирах корабля. Приведены пол, возраст, тип класса, и статус выживания для
пассажиров плохо снаряженных суден.
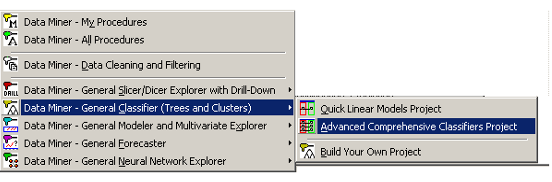
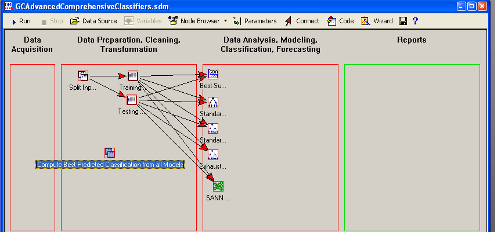
Отображаются единичная точка входа для
соединения с данными, а также различные точки для получения разных моделей из
данной информации.
Данный монтируется с помощью Training
sample, а затем оцениваются с помощью Testing sample.
В итоге Advanced Comprehensive Classifiers
Project предоставит различные методы классификации проблемы, и автоматически
сгенерирует развернутую информацию необходимую, чтоб классифицировать новые
наблюдения, используя один из этих методов или комбинации этих методов.
Проанализируем предикторы выживания в
случае катастрофы корабля.
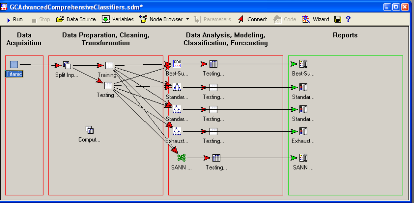
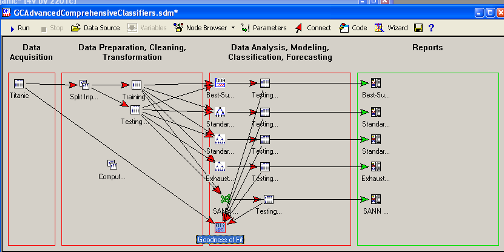
Запускаем проект:
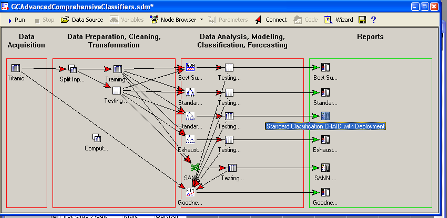
Результат:
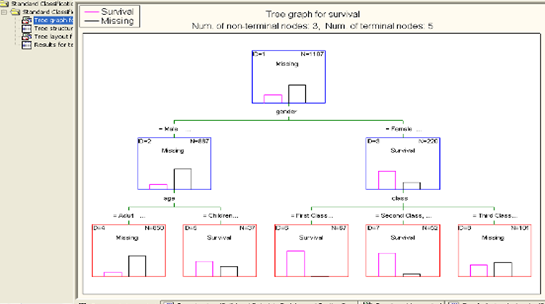
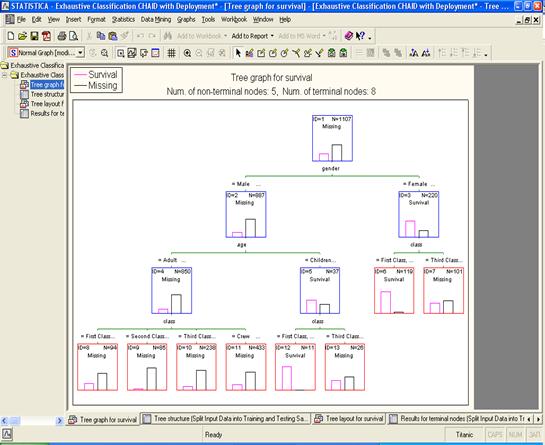
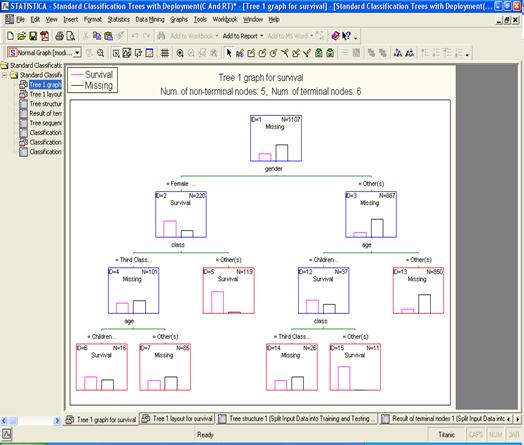
Если следовать этому дереву решений, вы
увидите, что женщины в первом и втором классах имеют более высокий шанс
выживания, чем дети мужского пола в первом и втором классах.
Заключение
Data Mining включает огромный набор
различных аналитических процедур, что делает его недоступным для обычных
пользователей, которые слабо разбираются в методах анализа данных. Компания
StatSoft нашла выход и из этой ситуации, данный пакет Statistica
могут использовать как профессионалы, так и обычные пользователи, обладающие
небольшими опытом и знаниями в анализе данных и математической статистике. Для
этого кроме общих методов анализа были встроены готовые законченные (сконструированные)
модули анализа данных, предназначенные для решения наиболее важных и популярных
задач: прогнозирования, классификации, создания правил ассоциации и т.д.


 Курсовая работа: Методы Data Mining
Курсовая работа: Методы Data Mining