

 Курсовая работа: Методы Data Mining
Курсовая работа: Методы Data Mining
Концептуально сегментирование основано на предпосылке, что все потребители - разные. У них разные потребности, разные требования к товару, они ведут себя по-разному: в процессе выбора товара, в процессе приобретения товара, в процессе использования товара, в процессе формирования реакции на товар. В связи с этим необходимо по-разному подходить к работе с потребителями: предлагать им различные по своим характеристикам товары, по-разному продвигать и продавать товары. Для того чтобы определить, чем отличаются потребители друг от друга и как эти отличия отражаются на требованиях к товару, и производится сегментирование потребителей.
В маркетинге критериями (характеристики) сегментации являются: географическое местоположение, социально-демографические характеристики, мотивы совершения покупки и т. п.
На основании результатов сегментации маркетолог может определить, например, такие характеристики сегментов рынка, как реальная и потенциальная емкость сегмента, группы потребителей, чьи потребности не удовлетворяются в полной мере ни одним производителем, работающим на данном сегменте рынка, и т. п. На основании этих параметров маркетолог может сделать вывод о привлекательности работы фирмы в каждом из выделенных сегментов рынка.
Для научных исследований изучение результатов кластеризации, а именно выяснение причин, по которым объекты объединяются в группы, способно открыть новые перспективные направления. Традиционным примером, который обычно приводят для этого случая, является периодическая таблица элементов. В 1869 г. Дмитрий Менделеев разделил 60 известных в то время элементов на кластеры или периоды. Элементы, попавшие в одну группу, обладали схожими характеристиками. Изучение причин, по которым элементы разбивались на явно выраженные кластеры, в значительной степени определило приоритеты научных изысканий на годы вперед. Но лишь спустя 50 лет квантовая физика дала убедительные объяснения периодической системы.
Кластеризация отличается от классификации тем, что для проведения анализа не требуется иметь выделенную зависимую переменную. С этой точки зрения она относится к классу unsupervised learning. Эта задача решается на начальных этапах исследования, когда о данных мало что известно. Ее решение помогает лучше понять данные, и с этой точки зрения задача кластеризации является описательной задачей.
Для задачи кластеризации характерно отсутствие каких-либо различий как между переменными, так и между объектами. Напротив, ищутся группы наиболее близких, похожих объектов. Методы автоматического разбиения на кластеры редко используются сами по себе, просто для получения групп схожих объектов. После определения кластеров применяются другие методы Data Mining, для того чтобы попытаться установить, а что означает такое разбиение, чем оно вызвано.
Кластерный анализ позволяет рассматривать достаточно большой объем информации и резко сокращать, сжимать большие массивы информации, делать их компактными и наглядными.
Отметим ряд особенностей, присущих задаче кластеризации.
Во-первых, решение сильно зависит от природы объектов данных (и их атрибутов). Так, с одной стороны, это могут быть однозначно определенные, четко количественно очерченные объекты, а с другой — объекты, имеющие вероятностное или нечеткое описание.
Во-вторых, решение значительно зависит также и от представления кластеров и предполагаемых отношений объектов данных и кластеров. Так, необходимо учитывать такие свойства, как возможность/невозможность принадлежности объектов нескольким кластерам. Необходимо определение самого понятия принадлежности кластеру: однозначная (принадлежит/не принадлежит), вероятностная (вероятность принадлежности), нечеткая (степень принадлежности).
Возможности Data Miner в Statistica 8
Компанией StatSoft была разработана система STATISTICA Data Miner, которая спроектирована и реализована как универсальное и всестороннее средство анализа данных - от взаимодействия с различными базами данных до создания готовых отчетов, реализующее так называемый графически - ориентированный подход. Чтобы описать все возможности данного пакета потребуется написать целую книгу, поэтому постараемся вкратце описать имеющиеся в данном пакете основные средства Data Mining.
· Наиболее полный пакет методов Data Mining на рынке программного обеспечения;
· Большой набор готовых решений;
· Удобный пользовательский интерфейс, полностью интегрированный с MS Office;
· Мощные средства разведочного анализа;
· Полностью оптимизированный пакет для работы с огромным объемом информации;
· Гибкий механизм управления;
· Многозадачность системы;
· Чрезвычайно быстрое и эффективное развертывание;
· Открытая COM архитектура, неограниченные возможности автоматизации и поддержки пользовательских приложений (использование промышленного стандарта Visual Basic (является встроенным языком), Java, C/C++).
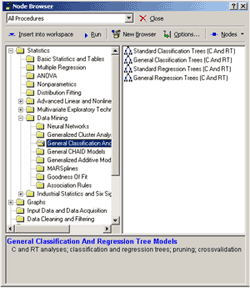
Сердцем STATISTICA Data Miner является браузер процедур Data Mining, содержащий более 300 основных процедур, специально оптимизированных под задачи Data Mining, и средств логической связи между ними и управления потоками данных, позволяющий конструировать собственные аналитические методы.
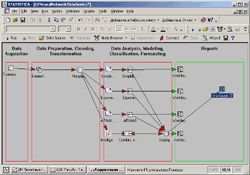
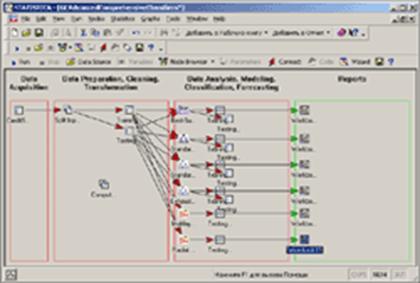
Рабочее пространство STATISTICA Data Miner состоит из четырех основных частей:
· Data Acquisition - Сбор данных. В данной части пользователь идентифицирует источник данных для анализа, будь то файл данных или запрос из базы данных.
· Data Preparation, Cleaning, Transformation - Подготовка, преобразования и очистка данных. Здесь данные преобразуются, фильтруются, группируются и т.д.
· Data Analysis, Modeling, Classification, Forecasting - Анализ данных, моделирование, классификация, прогнозирование. Здесь пользователь может при помощи браузера или готовых моделей задать необходимые виды анализа данных таких как, прогнозирование, классификация, моделирование и т.д.
· Reports - Результаты. В данной части пользователь может просмотреть, задать вид и настроить результаты анализа (например, рабочая книга, отчет или электронная таблица).
Средства анализа STATISTICA Data Miner
В пакете предлагается исчерпывающий набор процедур и методов визуализации.
Средства анализа STATISTICA Data Miner можно классифицировать на пять основных классов:
· ![]() General Slicer/Dicer and
Drill-Down Explorer - Разметка/Разбиение и Углубленный анализ. Набор процедур
позволяющий разбивать, группировать переменные, вычислять описательные
статистики, строить исследовательские графики и т.д.
General Slicer/Dicer and
Drill-Down Explorer - Разметка/Разбиение и Углубленный анализ. Набор процедур
позволяющий разбивать, группировать переменные, вычислять описательные
статистики, строить исследовательские графики и т.д.
· ![]() General Classifier -
Классификация. STATISTICA Data Miner включает в себя полный пакет процедур
классификации: обобщенные линейные модели, деревья классификации, регрессионные
деревья, кластерный анализ и т.д.
General Classifier -
Классификация. STATISTICA Data Miner включает в себя полный пакет процедур
классификации: обобщенные линейные модели, деревья классификации, регрессионные
деревья, кластерный анализ и т.д.
· ![]() General Modeler/Multivariate
Explorer - Обобщенные линейные, нелинейные и регрессионные модели. Данный
элемент содержит линейные, нелинейные, обобщенные регрессионные модели и
элементы анализа деревьев классификации.
General Modeler/Multivariate
Explorer - Обобщенные линейные, нелинейные и регрессионные модели. Данный
элемент содержит линейные, нелинейные, обобщенные регрессионные модели и
элементы анализа деревьев классификации.
· ![]() General Forecaster -
Прогнозирование. Включает в себя модели АРПСС, сезонные модели АРПСС,
экспоненциальное сглаживание, спектральный анализ Фурье, сезонная декомпозиция,
прогнозирование при помощи нейронных сетей и т.д.
General Forecaster -
Прогнозирование. Включает в себя модели АРПСС, сезонные модели АРПСС,
экспоненциальное сглаживание, спектральный анализ Фурье, сезонная декомпозиция,
прогнозирование при помощи нейронных сетей и т.д.
· ![]() General Neural Networks Explorer
- Нейросетевой анализ. В данной части содержится наиболее полный пакет процедур
нейросетевого анализа.
General Neural Networks Explorer
- Нейросетевой анализ. В данной части содержится наиболее полный пакет процедур
нейросетевого анализа.
Приведенные выше элементы являются комбинацией модулей других продуктов StatSoft, кроме них STATISTICA Data Miner содержит набор специализированных процедур Data Mining, которые дополняют линейку инструментов Data Mining
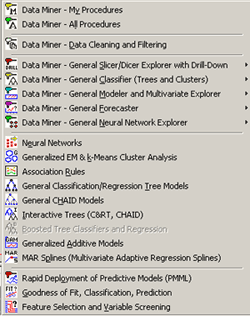
· Feature Selection and Variable Filtering (for very large data sets) - Специальная выборка и фильтрация данных (для больших объемов данных). Данный модуль автоматически выбирает подмножества переменных из заданного файла данных для последующего анализа. Например, модуль может обработать около миллиона входных переменных с целью определения предикторов для регрессии или классификации.
· Association Rules - Правила ассоциации. Модуль является реализацией так называемого априорного алгоритма обнаружения правил ассоциации например, результат работы этого алгоритма мог бы быть следующим: клиент после покупки продукт "А", в 95 случаях из 100, в течении следующих двух недель после этого заказывает продукт "B" или "С".
· Interactive Drill-Down Explorer - Интерактивный углубленный анализ. Представляет собой набор средств для гибкого исследования больших наборов данных. На первом шаге вы задаете набор переменных для углубленного анализа данных, на каждом последующем шаге вы выбираете необходимую подгруппу данных для последующего анализа.
· Generalized EM & k-Means Cluster Analysis - Обобщенный метод максимума среднего и кластеризация методом К средних. Данный модуль - это расширение методов кластерного анализа, предназначен для обработки больших наборов данных и позволяет кластеризовывать как непрерывные так и категориальные переменные, обеспечивает все необходимые функциональные возможности для распознавания образов.
