

 Курсовая работа: Методы Data Mining
Курсовая работа: Методы Data Mining
Другим примером задачи классификации является фильтрация электронной почты. В этом случае программа фильтрации должна классифицировать входящее сообщение как спам (нежелательная электронная почта) или как письмо. Данное решение принимается на основании частоты появления в сообщении определенных слов (например, имени получателя, безличного обращения, слов и словосочетаний: приобрести, "заработать", "выгодное предложение" и т. п.).
В общем случае количество классов в задачах классификации может быть более двух. Например, в задаче распознавания образа цифр таких классов может быть 10 (по количеству цифр в десятичной системе счисления). В такой задаче объектом классификации является матрица пикселов, представляющая образ распознаваемой цифры. При этом цвет каждого пиксела является характеристикой анализируемого объекта.
В Data Mining задачу классификации рассматривают как задачу определения 'значения одного из параметров анализируемого объекта на основании значений других параметров. Определяемый параметр часто называют зависимой переменной, а параметры, участвующие в его определении - независимыми переменными. В рассмотренных примерах независимыми переменными являлись:
· зарплата, возраст, количество детей и т. д.;
· частота определенных слов;
· значения цвета пикселов матрицы.
Зависимыми переменными в этих же примерах являлись:
· кредитоспособность клиента (возможные значения этой переменной "да" и "нет");
· тип сообщения (возможные значения этой переменной "spam" и "mail");
· цифра образа (возможные значения этой переменной 0, 1,..., 9).
Необходимо обратить внимание, что во всех рассмотренных примерах независимая переменная принимала значение из конечного множества значений: {да, нет}, {spam, mail}, {0, 1,..., 9}. Если значениями независимых и зависимой переменных являются действительные числа, то задача называется задачей регрессии. Примером задачи регрессии может служить задача определения суммы кредита, которая может быть выдана банком клиенту.
Задача классификации и регрессии решается в два этапа. На первом выделяется обучающая выборка. В нее входят объекты, для которых известны значения как независимых, так и зависимых переменных. В описанных ранее примерах такими обучающими выборками могут быть:
· информация о клиентах, которым ранее выдавались кредиты на разные суммы, и информация об их погашении;
· сообщения, классифицированные вручную как спам или как письмо;
· распознанные ранее матрицы образов цифр.
На основании обучающей выборки строится модель определения значения зависимой переменной. Ее часто называют функцией классификации или регрессии. Для получения максимально точной функции к обучающей выборке предъявляются следующие основные требования:
· количество объектов, входящих в выборку, должно быть достаточно большим. Чем больше объектов, тем построенная на ее основе функция классификации или регрессии будет точнее;
· в выборку должны входить объекты, представляющие все возможные классы в случае задачи классификации или всю область значений в случае задачи регрессии;
· для каждого класса в задаче классификации или каждого интервала области значений в задаче регрессии выборка должна содержать достаточное количество объектов.
На втором этапе построенную модель применяют к анализируемым объектам (к объектам с неопределенным значением зависимой переменной).
Задача классификации и регрессии имеет геометрическую интерпретацию. Рассмотрим ее на примере с двумя независимыми переменными, что позволит представить ее в двумерном пространстве (рис. 2.1.1). Каждому объекту ставится в соответствие точка на плоскости. Символы "+" и "-" обозначают принадлежность объекта к одному из двух классов. Очевидно, что данные имеют четко выраженную структуру: все точки класса "+" сосредоточены в центральной области. Построение классификационной функции сводится к построению поверхности, которая обводит центральную область. Она определяется как функция, имеющая значения "+" внутри обведенной области и "-" - вне.
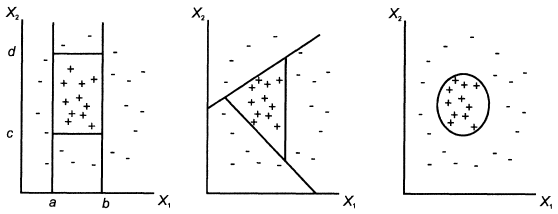
Рис. Классификация в двумерном пространстве
Как видно из рисунка, есть несколько возможностей для построения обводящей области. Вид функции зависит от применяемого алгоритма.
Основные проблемы, с которыми сталкиваются при решении задач классификации и регрессии, - это неудовлетворительное качество исходных данных, в которых встречаются как ошибочные данные, так и пропущенные значения, различные типы атрибутов - числовые и категорические, разная значимость атрибутов, а также так называемые проблемы overfitting и underfilling. Суть первой из них заключается в том, что классификационная функция при построении "слишком хорошо" адаптируется к данным, и встречающиеся в них ошибки и аномальные значения пытается интерпретировать как часть внутренней структуры данных. Очевидно, что такая модель будет некорректно работать в дальнейшем с другими данными, где характер ошибок будет несколько иной. Термином underfitting обозначают ситуацию, когда слишком велико количество ошибок при проверке классификатора на обучающем множестве. Это означает, что особых закономерностей в данных не было обнаружено и либо их нет вообще, либо необходимо выбрать иной метод их обнаружения.
Задача поиска ассоциативных правил
Поиск ассоциативных правил является одним из самых популярных приложений Data Mining. Суть задачи заключается в определении часто встречающихся наборов объектов в большом множестве таких наборов. Данная задача является частным случаем задачи классификации. Первоначально она решалась при анализе тенденций в поведении покупателей в супермаркетах. Анализу подвергались данные о совершаемых ими покупках, которые покупатели складывают в тележку (корзину). Это послужило причиной второго часто встречающегося названия — анализ рыночных корзин (Basket Analysis). При анализе этих данных интерес прежде всего представляет информация о том, какие товары покупаются вместе, в какой последовательности, какие категории потребителей, какие товары предпочитают, в какие периоды времени и т. п. Такая информация позволяет более эффективно планировать закупку товаров, проведение рекламной кампании и т. д.
Например, из набора покупок, совершаемых в магазине, можно выделить следующие наборы товаров, которые покупаются вместе:
· {чипсы, пиво};
· {вода, орехи}.
Следовательно, можно сделать вывод, что если покупаются чипсы или орехи, то, как правило, покупаются пиво или вода соответственно. Обладая такими знаниями, можно разместить эти товары рядом, объединить их в один пакет со скидкой или предпринять другие действия, стимулирующие покупателя приобрести товар.
Задача поиска ассоциативных правил актуальна не только в сфере торговли. Например, в сфере обслуживания интерес представляет, какими услугами клиенты предпочитают пользоваться в совокупности. Для получения этой информации задача решается применительно к данным об услугах, которыми пользуется один клиент в течение определенного времени (месяца, года). Это помогает определить, например, как наиболее выгодно составить пакеты услуг, предлагаемых клиенту.
В медицине анализу могут подвергаться симптомы и болезни, наблюдаемые у пациентов. В этом случае знания о том, какие сочетания болезней и симптомов встречаются наиболее часто, помогают в будущем правильно ставить диагноз.
При анализе часто вызывает интерес последовательность происходящих событий. При обнаружении закономерностей в таких последовательностях можно с некоторой долей вероятности предсказывать появление событий в будущем, что позволяет принимать более правильные решения. Такая задача является разновидностью задачи поиска ассоциативных правил и называется сиквенциалъным анализом.
Основным отличием задачи сиквенциального анализа от поиска ассоциативных правил является установление отношения порядка между исследуемыми наборами. Данное отношение может быть определено разными способами. При анализе последовательности событий, происходящих во времени, объектами таких наборов являются события, а отношение порядка соответствует хронологии их появления.
Сиквенциальный анализ широко используется, например в телекоммуникационных компаниях, для анализа данных об авариях на различных узлах сети. Информация о последовательности совершения аварий может помочь в обнаружении неполадок и предупреждении новых аварий. Например, если известна последовательность сбоев:
![]()
где ![]() — сбой с кодом i, то на
основании факта появления сбоя
— сбой с кодом i, то на
основании факта появления сбоя ![]() можно сделать вывод о скором
появлении сбоя
можно сделать вывод о скором
появлении сбоя ![]() . Зная это, можно предпринять
профилактические меры, устраняющие причины возникновения сбоя. Если
дополнительно обладать и знаниями о времени между сбоями, то можно предсказать
не только факт его появления, но и время, что часто не менее важно.
. Зная это, можно предпринять
профилактические меры, устраняющие причины возникновения сбоя. Если
дополнительно обладать и знаниями о времени между сбоями, то можно предсказать
не только факт его появления, но и время, что часто не менее важно.
Задача кластеризации
Задача кластеризации состоит в разделении исследуемого множества объектов на группы "похожих" объектов, называемых кластерами. Слово кластер английского происхождения (cluster), переводится как сгусток, пучок, группа. Родственные понятия, используемые в литературе, - класс, таксон, сгущение. Часто решение задачи разбиения множества элементов на кластеры называют кластерным анализом.
Кластеризация может применяться практически в любой области, где необходимо исследование экспериментальных или статистических данных. Рассмотрим пример из области маркетинга, в котором данная задача называется сегментацией.
