

 Реферат: Линейные списки. Стек. Дек. Очередь
Реферат: Линейные списки. Стек. Дек. Очередь
Иногда аналогия с переключением железнодорожных путей, предложенная Э. Дейкстрой, помогает понять механизм стека. На рис. 2. Изображен дек в виде железнодорожного разъезда.
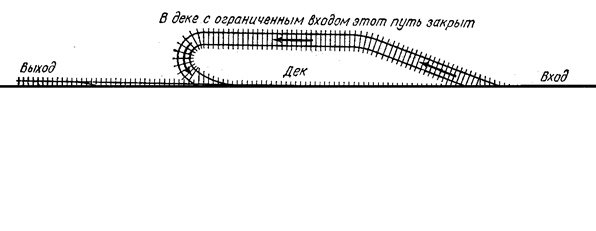
![]() Следовательно, дек
обладает большей общностью, чем стек или очередь; он имеет некоторые общие
свойства с колодой карт (в английском языке эти слова созвучны). Мы будем
различать деки с ограниченным выходом или ограниченным входом; в
таких деках соответственно исключение или включение допускается только на одном
конце.
Следовательно, дек
обладает большей общностью, чем стек или очередь; он имеет некоторые общие
свойства с колодой карт (в английском языке эти слова созвучны). Мы будем
различать деки с ограниченным выходом или ограниченным входом; в
таких деках соответственно исключение или включение допускается только на одном
конце.
В деке все исключения и добавления происходят на обоих его концах. Дек по сути двунаправленный список.
В связанном списке (linked list) элементы линейно упорядочены, но порядок определяется не номерами, как в массиве, а указателями, входящими в состав элементов списка. Списки являются удобным способом хранения динамических множеств, позволяющим реализовать все операции, (хотя и не всегда эффективно).
Если каждый стоящий в очереди запомнит, кто за ним стоит, после чего все в беспорядке рассядутся на лавочке, получится односторонне связанный список; если он запомнит ещё и впереди стоящего, будет двусторонне связанный список.
Другими словами, элемент двусторонне связанного списка (doubly linked list) — это запись, содержащая три поля: key (ключ) и два указателя — next (следующий) и prev (от previous—предыдущий). Помимо этого, элементы списка могут содержать дополнительные данные. Если х — элемент списка, то next указывает на следующий элемент списка, а prev — на предшествующий. Если prev{х}=nil, то у элемента х нет предшествующего: это голова (head) списка. Если next{х}= nil, то х — последний элемент списка или, как говорят, его хвост (tail).
Прежде чем двигаться по указателям, надо знать хотя бы один элемент списка. В различных ситуациях используются разные виды списков. В односторонне связанном (singly linked) списке отсутствуют поля prev. В упорядоченном (sorted) списке элементы расположены в порядке возрастания ключей, так что у головы списка ключ наименьший, а у хвоста списка — наибольший, в отличие от неупорядоченного (unsorted) списка. В кольцевом списке (circular list) поле prev головы списка указывает на хвост списка, а поле next хвоста списка указывает на голову списка.
 |
Если иное не оговорено особо, под списком мы будем понимать неупорядоченный двусторонне связанный список.
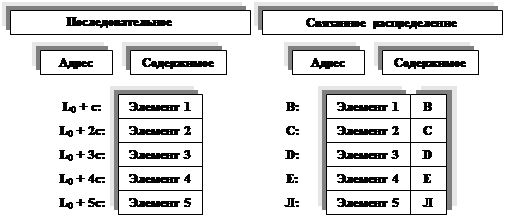
Вместо того чтобы хранить список в последовательных ячейках памяти, можно использовать значительно более гибкую схему, в которой каждый узел содержит связь со следующим узлом списка.
Здесь А, В, С, D и Е— произвольные ячейки в памяти, а Л — пустая связь. Программа, в которой используется такая таблица, имела бы, в случае последовательного распределения, дополнительную переменную или константу, значение которой показывает, что таблица состоит из пяти элементов; эту же информацию можно задать с помощью признака конца ("пограничника"), снабдив им элемент 5 или следующую ячейку, В случае связанного распределения в программе имеется переменная связи или константа, которая указывает на А, а отправляясь от А, можно найти все другие элементы списка.
Cвязи часто изображаются просто стрелками, поскольку, как правило, безразлично, какую фактическую ячейку памяти занимает элемент. Поэтому приведенную выше связанную, таблицу можно изобразить следующим образом:

Здесь FIRST — переменная связи, указывающая на первый узел в списке.
Теперь мы можем сопоставить эти две основные формы хранения информации:
1) Связанное распределение требует дополнительного пространства в памяти для связей. В некоторых ситуациях этот фактор может быть доминирующим. Однако мы часто встречаемся с таким положением, когда информация в узле не занимает все слово целиком, и поэтому место для поля связи уже существует. Кроме того, во многих применениях несколько элементов можно объединять в один узел, и, следовательно, потребуется лишь одна связь ни несколько элементов информации. Но гораздо важнее тот факт, что при использовании связанной памяти часто возникает неявный выигрыш в памяти, поскольку можно совмещать общие части таблиц; и во многих Случаях последовательное распределение не будет столь эффективным, как связанное, если так или иначе не остается пустым довольно большое количество ячеек памяти.
2) Легко исключить элемент, находящийся внутри связанного списка. Например, чтобы исключить элемент 3, нам необходимо только изменить связь в элементе 2. При последовательном же распределении такое исключение обычно потребует перемещения значительной части списка вверх на другие места памяти.
3) Если используется связанная схема, то легко включить
элемент в список. Например, чтобы включить элемент ![]() в
(1), необходимо изменить лишь две связи:
в
(1), необходимо изменить лишь две связи:
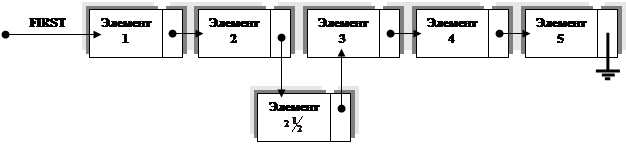
Такая операция заняла бы значительное время при работе с длинной последовательной
таблицей.
4) При последовательном распределении значительно быстрее выполняются обращения к произвольным частям списка. Доступ к k-му элементу списка, если k — переменная, для последовательного распределения занимает фиксированное время, а для связанного — необходимо k итераций, чтобы добраться до требуемого места. Таким образом, полезность связанной памяти основывается на том факте, что в огромном большинстве приложений мы будем продвигаться по списку последовательно, а не произвольным образом; если нам необходимы элементы в середине или в нижней части списка, то постараемся завести дополнительную переменную связи или список переменных связи, которые указывают на соответствующие места в списке.
5) При использовании схемы со связями упрощается задача объединения двух списков или разбиения списка на части.
6) Схема со связями годится для структур более сложных, чем простые линейные списки. У нас может быть переменное количество списков, размер которых непостоянен; любой узел одного списка может быть началом другого списка; в одно и то же время узлы могут быть связаны в несколько последовательностей, соответствующих различным спискам, и т.д.
7) На многих машинах простые операции, такие, как последовательное продвижение по списку, выполняются несколько быстрее для последовательных списков.
Таким образом, мы видим, что метод связывания, который освобождает нас от ограничений, возникающих вследствие последовательной природы машинной памяти, при некоторых операциях обеспечивает существенно большую эффективность, но в ряде случаев приводит к потере некоторых возможностей. Обычно в конкретной ситуации очевидно, какой метод распределения наиболее приемлем, и часто в программе для организации различных списков используются оба метода.
![]() В следующих нескольких
примерах мы будем ради удобства предполагать, что узел — это одно слово и что
оно разделено на два поля INFO и LINK:
В следующих нескольких
примерах мы будем ради удобства предполагать, что узел — это одно слово и что
оно разделено на два поля INFO и LINK:
Использование связанного распределения, как правило, предполагает существование некоторого механизма поиска пустого пространства для нового узла, когда мы хотим включить в список некоторую вновь образованную информацию. Для этой цели обычно существует специальный список, называемый списком свободного пространства.
 Циклическое
кольцо или список (circular list или ring) – файл, у которого нет определенного
начала и конца; каждый элемент файла содержит указатель на начало следующего элемента;
при этом «последний» элемент указывает на «первый», так что к списку можно
обратиться с любого элемента.
Циклическое
кольцо или список (circular list или ring) – файл, у которого нет определенного
начала и конца; каждый элемент файла содержит указатель на начало следующего элемента;
при этом «последний» элемент указывает на «первый», так что к списку можно
обратиться с любого элемента.

Циклически связанный список (сокращенно — циклический список)
обладает той особенностью, что связь его последнего узла не равна Л, а идет
назад к первому узлу списка. В этом случае можно получить доступ к любому
элементу, находящемуся в списке, отправляясь от любой заданной точки;
одновременно мы достигаем также полной симметрии, и теперь нам уже не
приходится различать в списке "последний" или "первый"
узел. Типичная ситуация выглядит следующим образом:
Предположим, в узлах имеется два поля: INFO и LINK. Переменная связи PTR указывает на самый правый узел списка, a LINK (PTR) является адресом самого левого узла.
Разного рода расщепления одного циклического списка на два, соответствуют операциям конкатенации (объединения) и деконкатенации (разъединения) цепочек.
Таким образом, мы видим, что циклические списки можно использовать не только для представления структур, которым свойственна цикличность, но также для представления линейных структур; циклический список с одним указателем на последний узел, по существу, эквивалентен простому линейному списку с двумя указателями на начало и конец. В связи с этим наблюдением возникает естественный вопрос: Как найти конец списка, имея в виду круговую симметрию? Пустой связи Л, которая отмечает конец, не существует. Проблема решается так: если мы выполняем некоторые операции, двигаясь по списку от одного узла к следующему, то мы должны остановиться, когда мы вернулись к исходному месту (предполагая, конечно, что исходное место все еще присутствует в списке).
Страницы: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13
