

 Курсовая работа: Розробка компілятора з вхідної мови програмування
Курсовая работа: Розробка компілятора з вхідної мови програмування
int is_ar;– кількість індексів масиву (для простої змінної – 0)
NODE* next; }– вказівник на наступний елемент списку
Кожен ідентифікатор, не знайдений в таблиці лексем, записується в таблицю лексем, що є двовимірним символьним масивом. Паралельно існує масив вказівників на список параметрів, в якому всі елементи, що відповідають функції, мають вказівник на список параметрів функції. Структура вузла цього списку:
FPAR {
int type;– тип параметра (1..4)
FPAR* next; }– вказівник на наступний елемент списку
Список лексем є вхідним для синтаксичного аналізатора, який є суміщений з семантичним. На виході синтаксичного аналізатора є інформація про аналіз, що записується у файл. Це є повідомлення про першу знайдену помилку або ж повідомлення про те, що помилок немає.
Якщо помилки немає, запускається транслятор, який транслює список лексем у файл на проміжній мові С++ відповідно до таблиці С-лексем і правил побудови вхідної мови.
Порміжний файл з розширенням с транслюється у ехе-файл стандартним компілятором bсс.ехе.
3.1.1 Розробка блок-схеми програми
Для побудови компілятора необхідно спроектувати його будову на рівні функцій і їх взаємозв'язків, тобто правил виклику. Це потрібно для побудови узгодженої багатомодульної структури при програмуванні зверху вниз. Кожну задачу розділяємо на дрібніші підзадачі, які потім в свою чергу уконкретнюємо.
Загальну структуру програми можна подати в такому спрощеному вигляді:
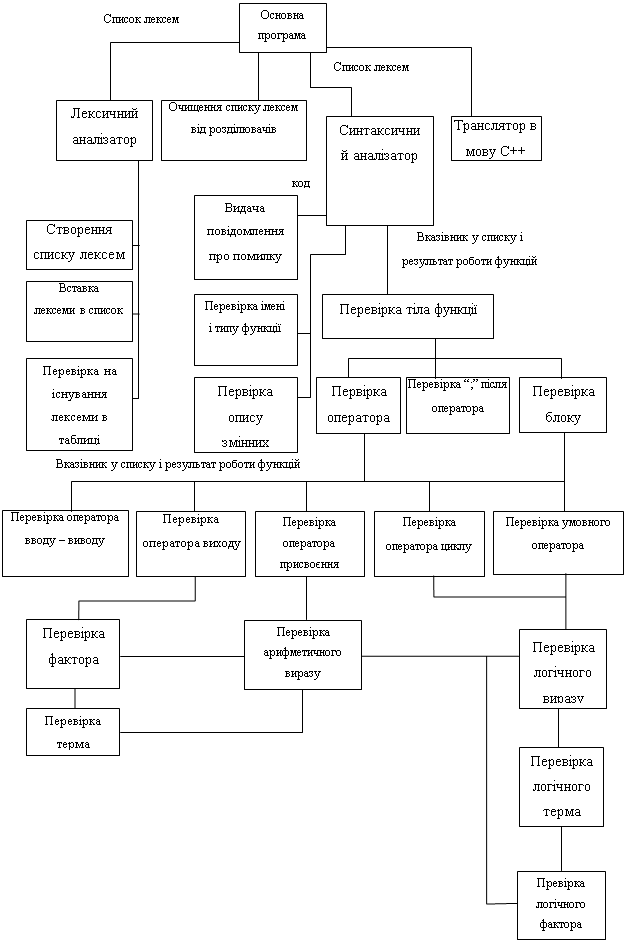
Рисунок 3 Загальна структура програми у спрощеному вигляді
3.2 Розробка синтаксичного аналізатора
Синтаксичний аналіз – це процес, в якому досліджується послідовність лексем, яку повернув лексичний аналізатор, і визначається, чи відповідає вона структурним умовам, що сформульовані у визначені синтаксису мови.
Синтаксичний аналізатор – це частина компілятора, яка відповідає за виявлення основних синтаксичних конструкцій вхідної мови. В задачу синтаксичного аналізатора входить: знайти та виділити основні синтаксичні конструкції мови в послідовності лексем програми, встановити тип та правильність побудови кожної синтаксичної конструкції і представити синтаксичні конструкції у вигляді, зручному для подальшої генерації тексту результуючої програми. Крім того, важливою функцією є локалізація синтаксичних помилок. Як правило, синтаксичні конструкції мови програмування можуть бути описані за допомогою контекстно-вільних граматик. Розпізнавач дає відповідь на питання, належить чи ні, ланцюжок вхідних лексем заданій мові. Але задача синтаксичного аналізу не обмежується тільки такою перевіркою. Синтаксичний аналізатор повинен мати деяку результуючу мову, за допомогою якої він передає наступним фазам компіляції інформацію про знайдені і розібрані синтаксичні конструкції, якщо відокремлюється фаза генерації об’єктного коду.
Кожна мова програмування має правила, які визначають синтаксичну структуру коректних програм. В Pascal, наприклад, програма створюється з блоків, блок – з інструкцій, інструкції – з виразів, вирази – з токенів і т.д. Синтаксис конструкцій мови програмування може бути описаний за допомогою контекстно-вільних граматик або нотації БНФ (Backus-Naur Form, форма Бекуса-Наура). Граматики забезпечують значні переваги розробникам мов програмування і авторам компіляторів.
Граматика дає точну і при цьому просту для розуміння синтаксичну специфікацію мови програмування.
Для деяких класів граматик можливо автоматично побудувати ефективний синтаксичний аналізатор, який визначає, чи коректна структура початкової програми. Додатковою перевагою автоматичного створення аналізатора є можливість виявлення синтаксичних неоднозначностей та інших складних для розпізнавання конструкцій мови, які інакше могли б залишитися непоміченими на початкових фазах створення мови і його компілятора.
Правильно побудована граматика додає мові програмування структуру, яка сприяє полегшенню трансляції початкової програми в об'єктний код і виявленню помилок. Для перетворення описів трансляції, заснованих на граматиці мови, в робочій програмі є відповідний програмний інструментарій.
З часом мови еволюціонують, збагатившись новими конструкціями і виконуючи нові задачі. Додавання конструкцій в мову виявиться більш простою задачею, якщо існуюча реалізація мови заснована на його граматичному описі.
Є три основні типи синтаксичних аналізаторів граматик. Універсальні методи розбору, такі як алгоритми Кока-Янгера-Касамі або Ерлі, можуть працювати з будь-якою граматикою. Проте ці методи дуже неефективні для використання в промислових компіляторах. Методи, які звичайно використовуються в компіляторах, класифікуються як низхідні (зверху вниз, top-down) або висхідні (з низу до верху, bottom-up). Як видно з назв, низхідні синтаксичні аналізатори будують дерево розбору зверху вниз (до листя), тоді як висхідні починають з листя і йдуть до кореня. В обох випадках вхідний потік синтаксичного аналізатора сканується посимвольно зліва направо. Найефективніші низхідні і висхідні методи працюють тільки з підкласами граматик, проте деякі з цих підкласів, такі як LL- і LR-граматики, достатньо виразні для опису більшості синтаксичних конструкцій мов програмування. Реалізовані вручну синтаксичні аналізатори частіше працюють з LL-граматиками. Синтаксичні аналізатори для дещо більшого класу LR-граматик звичайно створюються за допомогою автоматизованих інструментів. Будемо вважати, що вихід синтаксичного аналізатора є деяким представленням дерева розбору вхідного потоку токенів, виданого лексичним аналізатором. На практиці є безліч задач, які можуть супроводжувати процес розбору, - наприклад, збір інформації про різні токени в таблиці символів, виконання перевірки типів і інших видів семантичного аналізу, а також створення проміжного коду. Всі ці задачі представлені одним блоком "Інші задачі початкової фази компіляції" ( рисунок 4).
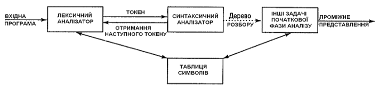
Рисунок 4 Місце синтаксичного аналізатора в моделі компілятора
3.2.1 Обробка синтаксичних помилок
Якщо компілятор матиме справу виключно з коректними програмами, його розробка і реалізація істотно спрощуються. Проте дуже часто програмісти пишуть програми з помилками, і добрий компілятор повинен допомогти програмісту знайти їх і локалізувати. Примітно, що хоча помилки — явище надзвичайно поширене, лише в декількох мовах питання обробки помилок розглядалося ще на фазі створення мови. Наша цивілізація істотно відрізнялася б від свого нинішнього стану, якби в природних мовах були такі ж вимоги до синтаксичної точності, як і в мовах програмування.
Більшість специфікацій мов програмування, проте, не визначає реакції компілятора на помилки — це питання віддається на відкуп розробникам компілятора. Проте планування системи обробки помилок з самого початку роботи над компілятором може як спростити його структуру, так і поліпшити його реакцію на помилки.
Будь-яка програма потенційно містить безліч помилок самого різного рівня. Наприклад, помилки можуть бути
• лексичними, такими як невірно записані ідентифікатори, ключові слова або оператори;
• синтаксичними, наприклад, арифметичні вирази з незбалансованими дужками;
• семантичними, такими як оператори, використані до несумісних операндів;
• логічними, наприклад нескінченна рекурсія.
Часто основні дії по виявленню помилок і відновленню після них концентруються у фазі синтаксичного аналізу. Одна з причин цього полягає в тому, що багато помилок за своєю природою є синтаксичними або виявляються, коли потік токенів, що йде від лексичного аналізатора, порушує визначаючі мова програмування граматичні правила. Друга причина полягає в точності сучасних методів розбору; вони дуже ефективно виявляють синтаксичні помилки в програмі. Визначення присутності в програмі семантичних або логічних помилок — задача набагато складніша.
Обробник помилок синтаксичного аналізатора має просту формульовану мету:
• він повинен ясно і точно повідомляти про наявність помилок;
• він повинен забезпечувати швидке відновлення після помилки, щоб продовжити пошук подальших помилок;
• він не повинен істотно уповільнювати обробку коректної програми.
Ефективна реалізація цієї мети є вельми складною задачею. На щастя, звичайні помилки достатньо прості, і для їх обробки часто достатньо простих механізмів обробки помилок.
В деяких випадках, проте, помилка може відбутися задовго до моменту її виявлення (і за багато рядків коду до місця її виявлення), і визначити її природу вельми непросто. В складних ситуаціях обробник помилок, по суті, повинен просто здогадатися, що саме мав на увазі програміст, коли писав програму. Деякі методи розбору, такі як LL і LR, виявляють помилки, як тільки це стає можливим. Точніше кажучи, вони володіють властивістю перевірки коректності префіксів, тобто виявляють помилку, як тільки з'ясовується що префікс вхідної інформації не є префіксом жодного коректного рядка мови.
3.3 Розробка семантичного аналізатора
В процесі роботи компілятор зберігає інформацію про об'єкти програми. Як правило, інформація про кожний об'єкт складається із двох основних елементів: імені об'єкта і його властивостей. Інформація про об'єкти програми повинна бути організована так, щоб пошук її був по можливості швидше, а необхідної пам'яті по можливості менше. Крім того, з боку мови програмування можуть бути додаткові вимоги.
Імена можуть мати певну область видимості. Наприклад поле запису повинне бути унікально в межах структури (або рівня структури), але може співпадати з ім'ям об'єктів зовні запису (або іншого рівня запису). В той же час ім'я поля може відкриватися оператором приєднання, і тоді може виникнути конфлікт імен (або неоднозначність в трактуванні імені). Якщо мова має блокову структуру, то необхідно забезпечити такий спосіб зберігання інформації, щоб, по-перше підтримувати блоковий механізм видимості, а по-друге – ефективно звільняти пам'ять по виході з блоку. В деяких мовах (наприклад, Аді) одночасно (в одному блоці) можуть бути видимі декілька об'єктів з одним ім'ям, в інших така ситуація неприпустима. Є декілька основних способів організації інформації в компіляторах:
