

 Курсовая работа: Розробка компілятора з вхідної мови програмування
Курсовая работа: Розробка компілятора з вхідної мови програмування
<statement>::= <declaration> | <operator>
<declaration>::=<type><ident>;
<operator>::=<bind> | <if-then-else> | <do-while > | <print>
<bind>::=<ident> = <expression>;
<if-then-else>::= if <bool expression> then <bloc> [else<bloc>]
<while-do>::= while <bool_ehpression> do <bloc>
<print>::= print <ident> | <int-const> | <log-const>;
<type>::= boolean | byte | ubyte
<ident>::=<letter> [{<letter>}]
<byte_corst>::= [] <number> [{<number>}]
<bool_const>::= true | false
<letter>::= a | …| z | A | … | Z
<number>::= 0 | 1 | … | 9
<logic.conct>::= true | fals
<expression>::=<num.expression>|<bool_expression>|<log.expression>
<num.expression>::=<num_operand>[{<num.operation><num.operand>}]
<bool_expression>::=<num.operand>[{<bool.operation><num_operand>}]
<logic_expression>::=<logic_operand>[]
<logic_operand>::= (<logic_expression>) | <ident>|<logic_const>
<num.operand>::=(<num.expression>) | <ident> | <byte_const>
<num.operation>::= * | / | + | - | ^
<bool_operation>::= < | > | = = | < >
<log_expression>::=<log_operand> [{NOT<log_operand>}]
<log_operand>:: (<log_expression>) | <cident> | <logic_const>
3. Розробка компілятора вхідної мови програмування
Процедурно-орієнтовані мови програмування, такі як FORTRAN, Pascal, C, C++ та ін. засновані на принципі послідовного виконання операторів, команд або директив. Їх базові оператори, операції, команди та директиви можна класифікувати по трьох основних групах:
а) Безумовні оператори (statements) обрахунків та перетворень;
б) Оператори обробки розгалужень та передачі управління;
в) Оператори організації циклічної обробки.
В загальному випадку віртуальна машина складається з інформаційного, операційного, управляючого та комунікаційного компонентів. Будь-яка віртуальна машина повинна мати:
а) Пам’ять різних видів та типів для збереження кодів програм і даних (інформаційний компонент) і механізми доступу до неї;
б) Вказівник поточної операції (основа управляючої компоненти), що змінюється при підрахунку номера оператора;
в) Блок виконання операцій (operators), який реалізує функції операційних та управляючих компонентів. Разом з інтерфейсним обладнанням він реалізує комунікаційний компонент, який забезпечує зв’язок ВМ із зовнішнім світом.
Загальна схема компілятора
Можна виділити сім різних логічних задач:
а. Інтерпретація – визначення точного змістового навантаження, створення матриці та таблиць з допомогою програм інтерпретації;
б. Машинно-незалежна оптимізація – створення оптимальнішої матриці;
в. Лексичний аналіз – розпізнавання базових елементів та створення стандартних символів;
г. Синтаксичний аналіз – розпізнавання базових синтаксичних конструкцій з використанням редукцій;
д. Розподіл пам’яті – модифікація таблиць ідентифікаторів та літералів. В матриці розміщується інформація, з допомогою якої генерується код, який розподіляє динамічну пам’ять;
е. Генерація коду – використання макропроцесора для отримання більш оптимального вихідного коду;
Фази з першої по четверту машинно-незалежні і визначаються тільки мовою. Фази з п’ятої по сьому – машинно-залежні і не залежать від мови. З метою забезпечення вищої ефективності ці фази можуть не розділятись так чітко.
Компілятор необхідно оцінювати не тільки по об’єктному коду, що генерується, але також і по об’єму оперативної пам’яті, що він займає і по часу, що потрібен для трансляції. На жаль, ці критерії оптимальності часто досить суперечливі. Крім того, оптимальність коду обернено пропорційна складності, розміру та часу роботи самого компілятора. Насправді необхідні компроміси.
Компілятором використовуються бази даних, що забезпечують зв’язки між фазами: вхідний код, таблиця стандартних символів, таблиця термінальних символів, таблиця ідентифікаторів, таблиця літералів, редукції, матриця, кодові продукції, код компоновки, кінцевий об’єктний код.
3.1 Розробка лексичного аналізатора
Для обробки текстів вхідних програм існує кілька способів побудови мовних процесорів. Одним з варіантів є інтерпретатор.
Інтерпретатор – це програма, яка обробляє вхідну програму, написану на вхідній мові і проводить обчислення, задані цією мовою.
Транслятор – програма, що обробляє вхідну програму, написану на вхідній мові і генерує програму на об’єктній мові. Об’єктна мова як правило є мовою деякої ЕОМ і таку програму одразу можна виконувати. Транслятори можна поділити на асемблери і компілятори, які транслюють відповідно мови низького і високого рівня.
Перед написанням компілятора вхідну мову потрібно подати в термінах деякої граматики. Ця граматика визначає форму або синтаксис допустимих виразів мови. Проблема компіляції – проблема пошуку в тексті вхідної програми конструкцій, що визначені граматикою та генерації відповідного коду для кожного виразу вхідної мови. Конструкції вхідної мови зручно подавати у вигляді лексем. Лексеми – це неділимі фундаментальні одиниці мови. Перегляд вхідного тексту та розпізнавання лексем називається лексичним аналізом, а процедура, яка його виконує – сканером. Після розпізнавання лексем кожен вираз можна розпізнати як окрему конструкцію мови, що описані граматикою. Цей процес називається синтаксичним аналізом.
Процес розробки компілятора можна зобразити такою схемою:
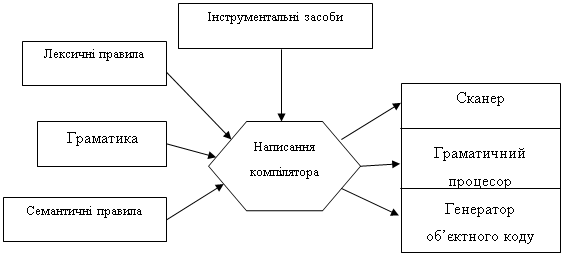
Рисунок 1 - Процес розробки компілятора.
Сканер або лексичний блок – одна з найпростіших частин компілятора. Він переглядає символи вхідної програми зліва направо і групує певні термінальні символи в єдині синтаксичні об’єкти. Цілі числа, ідентифікатори, символьні константи є нетермінальними символами і також групуються в таблиці.
Процес роботи лексичного аналізатора є складнішим. Побудований при лексичному аналізі список лексем проглядається зліва направо і аналізується. Є два основні способи для аналізу списку лексем. Це спосіб операторного передування і рекурсивний спуск.
Для роботи компілятора різна допоміжна інформація знаходиться в таблицях, якими дані передаються від одного до іншого етапу. В деяких реалізаціях записи, що заносяться в таблицю можуть мати різну довжину. Таким чином компілятору потрібні методи організації інформації, здатні швидко запам’ятати і видати інформацію про велику частину програми. Основну проблему синтаксичного аналізу можна сформулювати так: є велика кількість об’єктів, що можуть зустрічатися в програмі. Об'єкти можуть зустрічатися в непередбачуваному порядку. Як тільки об’єкт зустрівся, потрібно перевірити, чи не був він раніше занесений в таблицю. Якщо в таблиці об’єкту немає, його необхідно туди записати. Одним із способів запам'ятовування об'єктів є таблиці з прямим доступом.
При рекурсивному спуску відповідність блоків лексем синтаксичним правилам перевіряється відповідно до дерева розбору деякої конструкції.
Покажемо на прикладі дерево конструкції while мови С.
While (f+a*d) a=a+5;

Рисунок 2 Конструкції while мови С
При знаходженні ключового слова while перевіряється наявність дужки і викликається процедура перевірки запису виразу.
При перегляді виразу методом операторного передування лексеми проглядаються в обох напрямках, якщо це потрібно і визначається, чи порядок їх співпадає з описаними конструкціями.
На етапі синтаксичного аналізу визначаються помилки. Після того, як синтаксис оператора визначено, іде інтерпретація його значення, тобто семантичний аналіз. Кожній синтаксичній одиниці відповідає певне значення, яке може бути виражене в формі реальних входів або в проміжній формі. Проміжною формою синтаксичної конструкції є дерево розбору.
Після синтаксичного і семантичного аналізу тексту програми відбувається трансляція тексту в проміжну мову, якою у більшості випадків є асемблер. Трансляція тексту може відбуватись як за один, так і за декілька проходів. Перевагою однопрохідних компіляторів є те, що не потрібно підтримувати зв’язок між проходами, але недоліком є те, що всі змінні, функції, мітки і константи мусять обов’язково бути описані перед їх використанням.
Вибір структур вхідних данихПроцес компіляції вхідного файлу можна розділити умовно на кілька етапів. Основні етапи – це лексичний, синтаксичний та семантичний аналіз та трансляція. На кожному з цих етапів дані представляються у зручному для обробки вигляді.
Для лексичного аналізу вхідними даними є текстовий файл. Лексичний аналізатор формує динамічний список в основній пам'яті, в якому кожен вузол містить як інформацію про лексему, так і вказівник на наступну лексему. Останній вказівник має значення NULL. Структура вузла списку:
NODE
{ int line;– номер рядка лексеми
int idlexem;– код лексеми (номер у таблиці)
int type;– тип, якщо це ідентифікатор
int is_int;– чи це ідентифікатор, чи рядкова константа, чи число
