

 Курсовая работа: Дисперсионный анализ
Курсовая работа: Дисперсионный анализ
![]() (18)
(18)
где - вектор констант;
B0,..., Bp - матрицы;
t — ошибки.
Наличие в уравнении матрицы B0 означает возможность одновременного взаимодействия между n переменными; то есть B0 позволяет сделать так, чтобы эти переменные, относящиеся к одному моменту времени, определялись совместно.
Рекурсивную VAR можно оценить двумя способами. Рекурсивная структура дает набор рекурсивных уравнений, которые можно оценить с помощью МНК. Эквивалентный способ оценивания заключается в том, что уравнения приведенной формы (17), рассматриваемые как система, умножаются слева на нижнюю треугольную матрицу.
Метод оценивания структурной VAR зависит от того, как именно идентифицирована B0. Подход с частичной информацией влечет использование методов оценивания для отдельного уравнения, таких как двухшаговый метод наименьших квадратов. Подход с полной информацией влечет использование методов оценивания для нескольких уравнений, таких как трехшаговый метод наименьших квадратов.
Необходимо помнить о множественности различных типов VAR. Приведенная форма VAR единственна. Данному порядку переменных в Yt соответствует единственная рекурсивная VAR, но всего имеется n! таких порядков, т.е. n! различных рекурсивных VAR. Количество структурных VAR – то есть наборов предположений, которые идентифицируют одновременные взаимосвязи между переменными, - ограничено только изобретательностью исследователя.
Поскольку матрицы оцененных коэффициентов VAR затруднительно интерпретировать непосредственно, результаты оценивания VAR обычно представляют некоторыми функциями этих матриц. К таким статистикам разложения ошибки прогноза.
Разложения дисперсии ошибки прогноза вычисляются в основном для рекурсивных или структурных систем. Такое разложение дисперсии показывает, насколько ошибка в j-м уравнении важна для объяснения неожиданных изменений i-й переменной. Когда ошибки VAR некоррелированы по уравнениям, дисперсию ошибки прогноза на h периодов вперед можно записать как сумму компонентов, являющихся результатом каждой из этих ошибок /17/.
3.2 Факторный анализ
В современной статистике под факторным анализом понимают совокупность методов, которые на основе реально существующих связей признаков (или объектов) позволяют выявлять латентные обобщающие характеристики организационной структуры и механизма развития изучаемых явлений и процессов.
Понятие латентности в определении ключевое. Оно означает неявность характеристик, раскрываемых при помощи методов факторного анализа. Вначале имеется дело с набором элементарных признаков Xj, их взаимодействие предполагает наличие определенных причин, особенных условий, т.е. существование некоторых скрытых факторов. Последние устанавливаются в результате обобщения элементарных признаков и выступают как интегрированные характеристики, или признаки, но более высокого уровня. Естественно, что коррелировать могут не только тривиальные признаки Xj, но и сами наблюдаемые объекты Ni поэтому поиск латентных факторов теоретически возможен как по признаковым, так и по объектным данным.
Если объекты характеризуются достаточно большим числом элементарных признаков (m > 3), то логично и другое предположение - о существовании плотных скоплений точек (признаков) в пространстве n объектов. При этом новые оси обобщают уже не признаки Xj, а объекты ni, соответственно и латентные факторы Fr будут распознаны по составу наблюдаемых объектов:
Fr = c1n1 + c2n2 + ... + cNnN,
где ci - вес объекта ni в факторе Fr.
В зависимости от того, какой из рассмотренных выше тип корреляционной связи - элементарных признаков или наблюдаемых объектов - исследуется в факторном анализе, различают R и Q - технические приемы обработки данных.
Название R-техники носит объемный анализ данных по m признакам, в результате него получают r линейных комбинаций (групп) признаков: Fr=f(Xj), (r=1..m). Анализ по данным о близости (связи) n наблюдаемых объектов называется Q-техникой и позволяет определять r линейных комбинаций (групп) объектов: F=f(ni), (i = l .. N).
В настоящее время на практике более 90% задач решается при помощи R-техники.
Набор методов факторного анализа в настоящее время достаточно велик, насчитывает десятки различных подходов и приемов обработки данных. Чтобы в исследованиях ориентироваться на правильный выбор методов, необходимо представлять их особенности. Разделим все методы факторного анализа на несколько классификационных групп:
- Метод главных компонент. Строго говоря, его не относят к факторному анализу, хотя он имеет с ним много общего. Специфическим является, во-первых, то, что в ходе вычислительных процедур одновременно получают все главные компоненты и их число первоначально равно числу элементарных признаков. Во-вторых, постулируется возможность полного разложения дисперсии элементарных признаков, другими словами, ее полное объяснение через латентные факторы (обобщенные признаки).
- Методы факторного анализа. Дисперсия элементарных признаков здесь объясняется не в полном объеме, признается, что часть дисперсии остается нераспознанной как характерность. Факторы обычно выделяются последовательно: первый, объясняющий наибольшую долю вариации элементарных признаков, затем второй, объясняющий меньшую, вторую после первого латентного фактора часть дисперсии, третий и т.д. Процесс выделения факторов может быть прерван на любом шаге, если принято решение о достаточности доли объясненной дисперсии элементарных признаков или с учетом интерпретируемости латентных факторов.
Методы факторного анализа целесообразно разделить дополнительно на два класса: упрощенные и современные аппроксимирующие методы.
Простые методы факторного анализа в основном связаны с начальными теоретическими разработками. Они имеют ограниченные возможности в выделении латентных факторов и аппроксимации факторных решений. К ним относятся:
- однофакторная модель. Она позволяет выделить только один генеральный латентный и один характерный факторы. Для возможно существующих других латентных факторов делается предположение об их незначимости;
- бифакторная модель. Допускает влияние на вариацию элементарных признаков не одного, а нескольких латентных факторов (обычно двух) и одного характерного фактора;
- центроидный метод. В нем корреляции между переменными рассматриваются как пучок векторов, а латентный фактор геометрически представляется как уравновешивающий вектор, проходящий через центр этого пучка. : Метод позволяет выделять несколько латентных и характерные факторы, впервые появляется возможность соотносить факторное решение с исходными данными, т.е. в простейшем виде решать задачу аппроксимации.
Современные аппроксимирующие методы часто предполагают, что первое, приближенное решение уже найдено каким либо из способов, последующими шагами это решение оптимизируется. Методы отличаются сложностью вычислений. К этим методам относятся:
- групповой метод. Решение базируется на предварительно отобранных каким-либо образом группах элементарных признаков;
- метод главных факторов. Наиболее близок методу главных компонент, отличие заключается в предположении о существовании характерностей;
- метод максимального правдоподобия, минимальных остатков, а-факторного анализа канонического факторного анализа, все оптимизирующие.
Эти методы позволяют последовательно улучшить предварительно найденные решения на основе использования статистических приемов оценивания случайной величины или статистических критериев, предполагают большой объем трудоемких вычислений. Наиболее перспективным и удобным для работы в этой группе признается метод максимального правдоподобия.
Основной задачей, которую решают разнообразными методами факторного анализа, включая и метод главных компонент, является сжатие информации, переход от множества значений по m элементарным признакам с объемом информации n х m к ограниченному множеству элементов матрицы факторного отображения (m х r) или матрицы значений латентных факторов для каждого наблюдаемого объекта размерностью n х r, причем обычно r < m.
Методы факторного анализа позволяют также визуализировать структуру изучаемых явлений и процессов, а это значит определять их состояние и прогнозировать развитие. Наконец, данные факторного анализа дают основания для идентификации объекта, т.е. решения задачи распознавания образа.
Методы факторного анализа обладают свойствами, весьма привлекательными для их использования в составе других статистических методов, наиболее часто в корреляционно-регрессионном анализе, кластерном анализе, многомерном шкалировании и др. /18/.
3.3 Парная регрессия. Вероятностная природа регрессионных моделей.
Если рассмотреть задачу анализа расходов на питание в группах с одинаковыми доходами, например в $10.000(x), то это детерминированная величина. А вот Y - доля этих денег, затрачиваемая на питание - случайна и может меняться от года к году. Поэтому для каждого i-го индивида:
![]()
где εi - случайная ошибка;
α и β - константы (теоретически), хотя могут меняться от модели к модели.
Предпосылки для парной регрессии:
- X и Y связаны линейно;
- Х - неслучайная переменная с фиксированными значениями;
- ε - ошибки нормально распределены N(0,σ2);
-
![]() ;
;
-
![]() .
.
На рисунке 3.1 представлена модель парной регрессии.
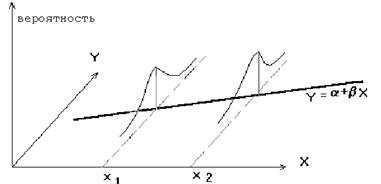
Рисунок 3.1 – Модель парной регрессии
Эти предпосылки описывают классическую линейную регрессионную модель.
Если ошибка имеет ненулевое среднее, исходная модель будет эквивалентна новой модели и другим свободным членом, но с нулевым средним для ошибки.
Если
выполняются предпосылки, то МНК оценки ![]() и
и
![]() являются эффективными
линейными несмещенными оценками
являются эффективными
линейными несмещенными оценками
![]()
Если обозначить:
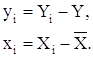
то
что математическое ожидание и дисперсии коэффициентов ![]() и
и
![]() будут следующие:
будут следующие:
![]()
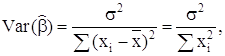
![]()
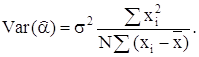
Ковариация коэффициентов:
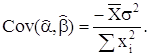
Если
![]() то
то ![]() и
и
![]() распределены тоже
нормально:
распределены тоже
нормально:
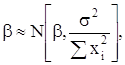
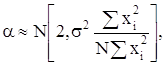
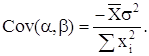
Отсюда следует, что:
- Вариация β полностью определяется вариацией ε;
- Чем выше дисперсия X - тем лучше оценка β.
Полная дисперсия определяется по формуле:
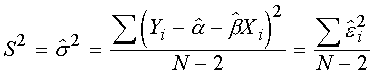
Дисперсия отклонений в таком виде - несмещенная оценка и называется стандартной ошибкой регрессии. N-2 - может быть интерпретировано как число степеней свободы.
Анализ отклонений от линии регрессии может представить полезную меру того, насколько оцененная регрессия отражает реальные данные. Хорошая регрессия та, которая объясняет значительную долю дисперсии Y и наоборот плохая регрессия не отслеживает большую часть колебаний исходных данных. Интуитивно ясно, что всякая дополнительная информация позволит улучшить модель, то есть уменьшить необъясненную долю вариации Y. Для анализа регрессионной модели проводят разложение дисперсии на составляющие, определяют коэффициент детерминации R2.
Отношение двух дисперсий распределено по F-распределению, т. е. если проверить на статистическую значимость отличия дисперсии модели от дисперсии остатков, можно сделать вывод о значимости R2.
Проверка гипотезы о равенстве дисперсий этих двух выборок:
![]()
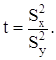
Если гипотеза Н0 (о равенстве дисперсий нескольких выборок) верна, t имеет F-распределение с (m1,m2)=(n1-1,n2-1) степенями свободы.
Посчитав F – отношение как отношение двух дисперсий и сравнив его с табличным значением, можно сделать вывод о статистической значимости R2 /2/, /19/.
Заключение
Современные приложения дисперсионного анализа охватывают широкий круг задач экономики, биологии и техники и трактуются обычно в терминах статистической теории выявления систематических различий между результатами непосредственных измерений, выполненных при тех или иных меняющихся условиях.
Благодаря автоматизации дисперсионного анализа исследователь может проводить различные статистические исследования с применение ЭВМ, затрачивая при этом меньше времени и усилий на расчеты данных. В настоящее время существует множество пакетов прикладных программ, в которых реализован аппарат дисперсионного анализа. Наиболее распространенными являются такие программные продукты как:
- MS Excel;
- Statistica;
- Stadia;
- SPSS.
В современных статистических программных продуктах реализованы большинство статистических методов. С развитием алгоритмических языков программирования стало возможным создавать дополнительные блоки по обработке статистических данных.
Дисперсионный анализ является мощным современным статистическим методом обработки и анализа экспериментальных данных в психологии, биологии, медицине и других науках. Он очень тесно связан с конкретной методологией планирования и проведения экспериментальных исследований.
Дисперсионный анализ применяется во всех областях научных исследований, где необходимо проанализировать влияние различных факторов на исследуемую переменную.
Список литературы
1 Кремер Н.Ш. Теория вероятности и математическая статистика. М.: Юнити – Дана, 2002.-343с.
2 Гмурман В.Е. Теория вероятностей и математическая статистика. – М.: Высшая школа, 2003.-523с.
3 www.sutd.ru
4 www.conf.mitme.ru
5 www.pedklin.ru
6 www.webcenter.ru
7 www.infections.ru
8 www.encycl.yandex.ru
9 www.infosport.ru
10 www.medtrust.ru
11 www.flax.net.ru
12 www.jdc.org.il
13 www.big.spb.ru
14 www.bizcom.ru
15 Гусев А.Н. Дисперсионный анализ в экспериментальной психологии. – М.: Учебно-методический коллектор «Психология», 2000.-136с.
16 www.gpss.ru
17 www.econometrics.exponenta.ru
18 www.optimizer.by.ru
19 www2.econ.msu.ru
