

 Реферат: Реляционные Базы Данных. SQL - стандартный язык реляционных баз данных
Реферат: Реляционные Базы Данных. SQL - стандартный язык реляционных баз данных
Реферат: Реляционные Базы Данных. SQL - стандартный язык реляционных баз данных
Содержание:
Содержание 2
- Реляционные базы данных 3
Что такое базы данных? 3
Первые модели данных 3
Системы управления файлами 3
Иерархические СУБД 4
Сетевые базы данных 5
Реляционная модель данных 7
Таблицы 8
Первичные ключи 9
Отношения предок/потомок 10
Внешние ключи 11
Двенадцать правил Кодда 12
- Язык SQL как стандартный язык баз данных 14
Язык SQL 15
Роль SQL 16
Достоинства SQL 17
Независимость от конкретных СУБД 18
Переносимость с одной вычислительной системы
на другую 18
Стандарты языка SQL 18
Одобрение SQL компанией IBM (DB2) 19
Протокол ODBC и компания Microsoft 19
Реляционная основа 19
Высокоуровневая структура,
напоминающая английский язык 20
Интерактивные запросы 20
Программный доступ к базе данных 20
Различные представления данных 20
Полноценный язык для работы с базами данных 20
Динамическое определение данных 21
Архитектура клиент/сервер 21
- Стандарты SQL 21
Стандарты ANSI/ISO 21
Другие стандарты SQL 22
ODBC и консорциум SQL Access Group 23
Миф о переносимости 23
- Влияние SQL 25
SQL и спецификация SAA компании IBM 25
SQL на мини-компьютерах 26
SQL на системах
UNIX 26
SQL и обработка
транзакций 26
SQL на персональных компьютерах 27
SQL в локальных сетях 28
Список использованной литературы 30
Список использованной литературы:
"SQL Полное руководство"
BHV, Киев, 1998
"Программирование в среде СУБД FoxPro 2.0"
Радио и связь, Москва, 1993
"Эффективная работа с Microsoft Access 7.0"
Питер, Санкт-Петербург, 1997
Санкт-Петербургский Государственный Технический Университет
Факультет Экономики и Менеджмента
![]()
Кафедра "Мировая Экономика"
РЕФЕРАТ
По Информатике
на тему:
"Реляционные Базы Данных.
SQL - стандартный язык реляционных баз данных"
Выполнил: Егоров С. Н. гр.2078/2
Проверил: Первицкий А. Ю.
![]()
Санкт-Петербург
1999
1. Реляционные базы данных
Что такое базы данных?
В самом общем смысле база данных - это набор записей и файлов, организованных специальным образом. В компьютере, например, можно хранить фамилии и адреса друзей или клиентов. Один из типов баз данных - это документы, набранные с помощью текстовых редакторов и сгруппированные по темам. Другой тип - файлы электронных таблиц, объединяемые в группы по характеру их использования.
Первые модели данных
С ростом популярности СУБД в 70-80-х годах появилось множество различных моделей данных. У каждой из них имелись свои достоинства и недостатки, которые сыграли ключевую роль в развитии реляционной модели данных, появившейся во многом благодаря стремлению упростить и упорядочить первые модели данных.
Системы управления файлами.
До появления СУБД все данные, которые содержались в компьютерной системе постоянно, хранились в виде отдельных файлов. Система управления файлами, которая обычно является частью операционной системы компьютера, следила за именами файлов и местами их расположения. В системах управления файлами модели данных, как правило, не использовались; эти системы ничего не знали о внутреннем содержимом файлов. Для такой системы файл, содержащий документ текстового процессора, ничем не отличается от файла, содержащего данные о начисленной зарплате.
З
Рис 1.1. Приложение для начисления зарплаты, использующее систему управления файлами.
Программа для обновления данных по служащим
ОСД
Программа для начисления зарплаты
ОСД
ОСД
Программа для создания отчетов по служащим
ОСД




Рис. 1.1. Приложение для начисления зарплаты, использующее систему управления файлами.
нание о содержимом файла - какие данные в нём хранятся и какова их структура - было уделом прикладных программ, использующих этот файл, что иллюстрирует рис. 1.1. В приложении для начисления зарплаты каждая из программ, обрабатывающих файл с информацией о служащих, содержит в себе описание структуры данных (ОСД), хранящихся в этом файле. Когда структура данных изменялась - например, в случае добавления нового элемента данных для каждого служащего, - необходимо было модифицировать каждую из программ, обращавшихся к файлу. Со временем количество файлов и программ росло, и на сопровождение существующих приложений приходилось затрачивать всё больше и больше усилий, что замедляло разработку новых приложений.Проблемы сопровождения больших систем, основанных на файлах, привели в конце 60-х годов к появлению СУБД. В основе СУБД лежала простая идея: изъять из программ определение структуры содержимого файла и хранить её вместе с данными в базе данных.
Иерархические СУБД
Одной из наиболее важных сфер применения первых СУБД было планирование производства для компаний, занимающихся выпуском продукции. Например, если автомобильная компания хотела выпустить 10000 машин одной модели и 5000 машин другой модели, ей необходимо было знать, сколько деталей следует заказать у своих поставщиков. Чтобы ответить на этот вопрос, необходимо определить, из каких деталей состоят эти части и т.д. Например, машина состоит из двигателя, корпуса и ходовой части; двигатель состоит из клапанов, цилиндров, свеч и т.д. Работа со списками составных частей была как будто специально предназначена для компьютеров.
С
Рис 1.2. Иерархическая база данных, содержащая информацию о составных частях

















Записи
В этой модели каждая запись базы данных представляла конкретную деталь. Между записями существовали отношения предок/потомок, связывающие каждую часть с деталями, входящими в неё.
Чтобы получить доступ к данным, содержащимся в базе данных, программа могла:
найти конкретную деталь (правую дверь) по её номеру;
перейти "вниз" к первому потомку (ручка двери);
перейти "вверх" к предку (корпус);
перейти "в сторону" к другому потомку (правая дверь).
Таким образом, для чтения данных из иерархической базы данных требовалось перемещаться по записям, за один раз переходя на одну запись вверх, вниз или в сторону.
Одной из наиболее популярных иерархических СУБД была Information Management System (IMS) компании IBM, появившаяся в 1968 году. Ниже перечислены преимущества IMS и реализованной в ней иерархической модели.
Простота модели. Принцип построения IMS был легок для понимания. Иерархия базы данных напоминала структуру компании или генеалогическое дерево.
Использование отношений предок/потомок. СУБД IMS позволяла легко представлять отношения предок/потомок, например: "А является частью В" или "А владеет В".
Быстродействие. В СУБД IMS отношения предок/потомок были реализованы в виде физических указателей из одной записи на другую, вследствие чего перемещение по базе данных происходило быстро. Поскольку структура данных в этой СУБД отличалась простотой, IMS могла размещать записи предков и потомков на диске рядом друг с другом, что позволяло свести к минимуму количество операций записи-чтения.
СУБД IMS все ещё является одной из наиболее распространённых СУБД для больших ЭВМ компании IBM. Доля мэйнфреймов этой компании, на которых используется данная СУБД, превышает 25%.
С

Клиенты
Служащие
Товары
 етевые
базы данных
етевые
базы данных
Е










Заказы

Рис. 1.3. Множественные отношения предок/потомок
сли структура данных оказывалась сложнее, чем обычная иерархия, простота структуры иерархической базы данных становилась её недостатком. Например, в базе данных для хранения заказов один заказ мог участвовать в трёх различных отношениях предок/потомок, связывающих заказ с клиентом, разместившим его, со служащим, принявшим его, и с заказанным товаром, что иллюстрирует рис. 1.3. Такие структуры данных не соответствовали строгой иерархии IMS.
В связи с этим
для таких приложений,
как обработка
заказов, была
разработана
новая сетевая
модель данных.
Она являлась
улучшенной
иерархической
м![]() оделью,
в которой одна
запись могла
участвовать
в нескольких
отношениях
предок/потомок,
как показано
на рис. 1.4. В сетевой
модели такие
отношения
назывались
множествами.
В 1971 году на конференции
по языкам систем
данных был
опубликован
официальный
стандарт сетевых
баз данных,
который известен
как модель
CODASYL.
Компания IBM
не стала разрабатывать
собственную
сетевую СУБД
и вместо этого
продолжала
наращивать
возможность
IMS.
Но в 70-х годах
независимые
производители
программного
обеспечения
реализовали
сетевую модель
в таких продуктах,
как IDMS
компании Cullinet,
Total к
оделью,
в которой одна
запись могла
участвовать
в нескольких
отношениях
предок/потомок,
как показано
на рис. 1.4. В сетевой
модели такие
отношения
назывались
множествами.
В 1971 году на конференции
по языкам систем
данных был
опубликован
официальный
стандарт сетевых
баз данных,
который известен
как модель
CODASYL.
Компания IBM
не стала разрабатывать
собственную
сетевую СУБД
и вместо этого
продолжала
наращивать
возможность
IMS.
Но в 70-х годах
независимые
производители
программного
обеспечения
реализовали
сетевую модель
в таких продуктах,
как IDMS
компании Cullinet,
Total к





![]()

![]()

![]()

![]()
![]()
![]()
Рис. 1.4. Сетевая база данных, содержащая информацию о заказах
Клиенты
Товары
Заказы
Записи
Множество
 омпании
Cincom и
СУБД Adabas,
которые приобрели
большую популярность.
омпании
Cincom и
СУБД Adabas,
которые приобрели
большую популярность.
Сетевые базы данных обладали рядом преимуществ:
Гибкость. Множественные отношения предок/потомок позволяли сетевой базе данных хранить данные, структура которых была сложнее простой иерархии.
Стандартизация. Появление стандарта CODASYL популярность сетевой модели, а такие поставщики мини-компьютеров, как Digital Equipment Corporation и Data General, реализовали сетевые СУБД.
Быстродействие. Вопреки своей большой сложности, сетевые базы данных достигали быстродействия, сравнимого с быстродействием иерархических баз данных. Множества были представлены указателями на физические записи данных, и в некоторых системах администратор мог задать кластеризацию данных на основе множества отношений.
Конечно, у сетевых баз данных были недостатки. Как и иерархические базы данных, сетевые базе данных были очень жесткими. Наборы отношений и структуру записей приходилось задавать наперёд. Изменение структуры базы данных обычно означало перестройку всей базы данных.
Как иерархическая, так и сетевая база данных были инструментами программистов. Чтобы получить ответ на вопрос типа "Какой товар наиболее часто заказывает компания Acme Manufacturing?", программисту приходилось писать программу для навигации по базе данных. Реализация пользовательских запросов часто затягивалась на недели и месяцы, и к моменту появления программы информация, которую она предоставляла, часто оказывалась бесполезной.
Реляционная модель данных
Недостатки иерархической и сетевой моделей привели к появлению новой, реляционной модели данных, созданной Коддом в 1970 году и вызвавшей всеобщий интерес. Реляционная модель была попыткой упростить структуру базы данных. В ней отсутствовали явные указатели на предков и потомков, а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы. На рис. 1.5. показана реляционная версия сетевой базы данных, содержащей информацию о заказах и приведенной на рис. 1.4.
К сожалению, практическое определение понятия "реляционная база данных" оказалось гораздо более расплывчатым, чем точное математическое определение, данное этому термину Коддом в 1970 году. В первых реляционных СУБД не были реализованы некоторые из ключевых частей модели Кодда, и этот пробел был восполнен только впоследствии. По мере роста популярности реляционной концепции реляционными стали называться многие базы данных, которые на деле таковыми не являлись.


| Таблица CUSTOMERS | ||
|
COMPANY |
CUST_REP |
CREDIT_LIMIT |
|
JSP Inc. |
103 |
$50,000.00 |
|
First Corp. |
101 |
$65,000.00 |
Рис. 1.5. Реляционная база данных, содержащая информацию о заказах
В ответ на неправильное использование термина "реляционный" Кодд в 1985 году написал статью, где сформулировал 12 правил, которым должна удовлетворять любая база данных, претендующая на звание реляционной. С тех пор двенадцать правил Кодда считаются определением реляционной СУБД. Однако можно сформулировать и более простое определение:
Реляционной называется база данных, в которой все данные, доступные пользователю, организованны в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами.
Приведенное определение не оставляет места встроенным указателям, имеющимся в иерархических и сетевых СУБД. Несмотря на это, реляционная СУБД также способна реализовать отношения предок/потомок, однако эти отношения представлены исключительно значениями данных, содержащихся в таблицах.
Таблицы
В
| Таблица OFFICES | |||||
|
OFFICE |
CITY |
REGION |
MGR |
TARGET |
SALES |
|
22 |
Denver |
Western |
108 |
$300,000.00 |
$186,042.00 |
|
11 |
New York |
Easten |
106 |
$575,000.00 |
$692,000.00 |
|
12 |
Chicago |
Easten |
104 |
$800,000.00 |
$739,000.00 |
|
13 |
Atlanta |
Easten |
105 |
$350,000.00 |
$735,157.00 |
|
21 |
Los Angeles |
Western |
108 |
$725,000.00 |
$835,915.00 |
Город, в котором расположен офис
Идентификатор служащего, управляющего офисом
Объём продаж офиса с начала года
Данные об офисе в Нью-Йорке
Данные об офисе в Лос-Анджелесе
Рис. 1.6. Структура реляционной таблицы.
реляционной базе данных информация организована в виде таблиц, разделённых на строки и столбцы, на пересечении которых содержатся значения данных. У каждой таблицы имеется уникальное имя, описывающее её содержимое. Более наглядно структуру таблицы иллюстрирует рис 1.6., на котором изображена таблица OFFICES. Каждая горизонтальная строка этой таблицы представляет отдельную физическую сущность - один офис. Пять строк таблицы вместе представляют все пять офисов компании. Все данные, содержащиеся в конкретной строке таблицы, относятся к офису, который описывается этой строкой.Каждый вертикальный столбец таблицы OFFICES представляет один элемент данных для каждого из офисов. Например, в столбце CITY содержатся названия городов, в которых расположены офисы. В столбце SALES содержатся объёмы продаж, обеспечиваемые офисами.
На пересечении каждой строки с каждым столбцом таблицы содержится в точности одно значение данных. Например, в строке, представляющей нью-йоркский офис, в столбце CITY содержится значение "New York". В столбце SALES той же строки содержится значение $692.000.000, которое является объёмом продаж нью-йоркского офиса с начала года.
Все значения, содержащиеся в одном и том же столбце, являются данными одного типа. Например, в столбце CITY содержатся только слова, в столбце SALES содержатся денежные суммы, а в столбце MGR содержатся целые числа, представляющие идентификаторы служащих. Множество значений, которые могут содержаться в столбце, называется доменом этого столбца. Доменом столбца CITY является множество названий городов. Доменом столбца SALES является любая денежная сумма. Домен столбца REGION состоит всего из двух значений, "Eastern" и "Western", поскольку у компании всего два торговых региона.
У каждого столбца в таблице есть своё имя, которое обычно служит заголовком столбца. Все столбцы в одной таблице должны иметь уникальные имена, однако разрешается присваивать одинаковые имена столбцам, расположенным в различных таблицах. На практике такие имена столбцов, как NAME, ADDRESS, QTY, PRICE и SALES, часто встречаются в различных таблицах одной базы данных.
Столбцы таблицы упорядочены слева направо, и их порядок определяется при создании таблицы. В любой таблице всегда есть как минимум один столбец. В стандарте ANSI/ISO не указывается максимально допустимое число столбцов в таблице, однако почти во всех коммерческих СУБД этот предел существует и обычно составляет примерно 255 столбцов.
В отличие от столбцов, строки таблицы не имеют определённого порядка. Это значит, что если последовательно выполнить два одинаковых запроса для отображения содержимого таблицы, нет гарантии, что оба раза строки будут перечислены в одном и том же порядке.
В таблице может содержаться любое количество строк. Вполне допустимо существование таблицы с нулевым количеством строк. Такая таблица называется пустой. Пустая таблица сохраняет структуру, определённую её столбцами, просто в ней не содержится данные. Стандарт ANSI/ISO не накладывает ограничений на количество строк в таблице, и во многих СУБД размер таблиц ограничен лишь свободным дисковым пространством компьютера. В других СУБД имеется максимальный предел, однако он весьма высок - около двух миллиардов строк, а иногда и больше.
Первичные ключи
Поскольку строки в реляционной таблице не упорядочены, нельзя выбрать строку по ее номеру в таблице. В таблице нет "первой", "последней" или "тринадцатой" строки. Тогда каким же образом можно указать в таблице конкретную строку, например строку для офиса, расположенного в Денвере?
В правильно построенной реляционной базе данных в каждой таблице есть один или несколько столбцов, значения в которых во всех строках разные. Этот столбец (столбцы) называется первичным ключом таблицы. Давайте вновь посмотрим на базу данных, показанную на рис. 1.6. На первый взгляд, первичным ключом таблицы OFFICES могут служить и столбец OFFICE, и столбец CITY. Однако в случае, если компания будет расширяться и откроет в каком-либо городе второй офис, столбец CITY больше не сможет выполнять роль первичного ключа. На практике в качестве первичных ключей таблиц обычно следует выбирать идентификаторы, такие как идентификатор офиса (OFFICE в таблице OFFICES), служащего (EMPL_NUM в таблице SALESREPS) и клиента (CUST_NUM в таблице CUSTOMES). А в случае; с таблицей ORDERS выбора нет — единственным столбцом, содержащим уникальные значения, является номер заказа (ORDER_NUM).
Таблица
PRODUCTS,
фрагмент
которой показан
на рис.
1.7, является
примером таблицы,
в которой первичный
ключ представляет
собой комбинацию
столбцов. Такой
первичный ключ
называется
составным.
Столбец MRF_ID
содержит
идентификаторы
производителей
всех товаров,
перечисленных
в таблице, а
столбец
PRODUCT_ID
содержит
номера, присвоенные
товарам производителями.
Может показаться,
что столбец
PRODUCT_ID
мог бы
и один выполнять
роль первичного
ключа, однако
ничто не мешает
двум различным
производителям
присвоить своим
изделиям одинаковые
номера. Таким
образом, в качестве
первичного
ключа таблицы
PRODUCTS
необходимо
использовать
комбинацию
столбцов
MRF_ID
и
PRODUCT_ID.
Для каждого
из товаров,
содержащихся
в таблице, к
| Таблица PRODUCTS | ||||
|
MFR_ID |
PRODUCT_ID |
DESCRIPTION |
PRICE |
QTY_ON_HAND |
|
REI |
2A45C |
Ratchet Link |
$79.00 |
210 |
|
ACI |
4100Y |
Widget Remover |
$2,750.00 |
25 |
|
QSA |
KX47 |
Reducer |
$355.00 |
38 |
|
BIC |
41672 |
Plate |
$180.00 |
0 |
Первичный ключ
Рис. 1.7. Пример таблицы с составным первичным ключом
омбинация значений в этих столбцах будет уникальной.Первичный ключ для каждой строки таблицы является уникальным, поэтому в таблице с первичным ключом нет двух совершенно одинаковых строк. Таблица, в которой все строки отличаются друг от друга, в математических терминах называется отношением. Именно этому термину реляционные базы данных и обязаны своим названием, поскольку в их основе лежат отношения (таблицы с отличающимися друг от друга строками).
Хотя первичные ключи являются важной частью реляционной модели данных, в первых реляционных СУБД (System/R, DB2, Oracle и других) не была обеспечена явным образом их поддержка. Как правило, проектировщики базы данных сами следили за тем, чтобы у всех таблиц были первичные ключи, однако в самих СУБД не было возможности определить для таблицы первичный ключ. И только в СУБД DB2 Version 2, появившейся в апреле 1988 года, компания IBM реализовала поддержку первичных ключей. После этого подобная поддержка была добавлена в стандарт ANSI/ISO.
Отношения предок/потомок
Одним из отличий реляционной модели от первых моделей представления данных было то, что в ней отсутствовали явные указатели, используемые для реализации отношений предок/потомок в иерархической модели данных. Однако вполне очевидно, что отношения предок/потомок существуют и в реляционных базах данных. Например, в нашей базе данных каждый из служащих закреплен за конкретным офисом, поэтому ясно, что между строками таблицы OFFICES и таблицы SALESREPS существует отношение. Не приводит ли отсутствие явных указателей в реляционной модели к потере информации?
Как следует
из рис.
1.8, ответ
на этот вопрос
должен быть
отрицательным.
На рисунке
изображено
несколько строк
из таблиц
OFFICES
и
SALESREPS. Обратим
внимание на
то, что в столбце
REP_OFFICE таблицы
SALESREPS содержится
идентификатор
офиса, в котором
работает служащий.
Доменом этого
столбца (множеством
значений, которые
могут в нем
храниться)
является множество
идентификаторов
офисов, содержащихся
в столбце OFFICE
таблицы
OFFICES.
То, в каком
офисе работает
Мэри Джонс
(Магу Jones),
можно узнать,
определив
значение столбца
REP_OFFICE
в строке
таблицы
SALESREPS
для Мэри
Джонс (число
II) и затем
отыскав в таблице
OFFICES
строку с
таким же значением
в столбце
OFFICE
(это для
офиса в Нью-Йорке).
Таким же образом,
чтобы найти
всех служащих
нью-йоркского
офиса, следует
запомнить
значение столбца
OFFICE
для Нью-Йорка
(число
II), а потом
просмотреть
таблицу
SALESREPS
и найти все
строки, в столбце
REP_OFFICE
которых
содержится
число
11 (это строки
для Мэри Джонс
и С
| Таблица OFFICES | ||
|
OFFICE |
CITY |
REGION |
|
22 |
Denver |
Western |
|
11 |
New York |
Eastern |
|
12 |
Chicago |
Eastern |
| Таблица SALESREPS | |||
|
EMPL_NUM |
NAME |
AGE |
REP_OFFICE |
|
105 |
Bill Adams |
37 |
13 |
|
109 |
Mary Jones |
31 |
11 |
|
102 |
Sue Smith |
48 |
21 |
|
106 |
Sam Clark |
52 |
11 |
Рис. 1.8. Отношение предок/потомок в реляционной базе данных
эма Кларка (Sam Clark)).Отношение предок/потомок, существующее между офисами и работающими в них людьми, в реляционной модели не потеряно; просто оно реализовано в виде одинаковых значений данных, хранящихся в двух таблицах, а не в виде явного указателя. Все отношения, существующие между таблицами реляционной базы данных, реализуются в таком виде.
Внешние ключи
Столбец одной таблицы, значения в котором совпадают со значениями столбца, являющегося первичным ключом другой таблицы, называется внешним ключом. На рис. 4.9 столбец REP_OFFICE представляет собой внешний ключ для таблицы OFFICES. Значения, содержащиеся в этом столбце, представляют собой идентификаторы офисов. Эти значения соответствуют значениям в столбце OFFICE, который является первичным ключом таблицы OFFICES. Совокупно первичный и внешний ключи создают между таблицами, в которых они содержатся, такое же отношение предок/потомок, как и в иерархической базе данных.
Внешний ключ, как и первичный ключ, тоже может представлять собой комбинацию столбцов. На практике внешний ключ всегда будет составным (состоящим из нескольких столбцов), если он ссылается на составной первичный ключ в другой таблице. Очевидно, что количество столбцов и их типы данных в первичном и внешнем ключах совпадают.
Если таблица связана с несколькими другими таблицами, она может иметь несколько внешних ключей. На рис. 1.9. показаны три внешних ключа таблицы ORDERS из учебной базы данных:
столбец REP является внешним ключом для таблицы SALESREPS и
связывает каждый заказ со служащим, принявшим его;столбец CUST является внешним ключом для таблицы CUSTOMES и
связывает каждый заказ с клиентом, разместившим его;столбцы MRF и PRODUCT совокупно представляют собой составной внешний ключ для таблицы PRODUCTS, который связывает каждый заказ с заказанным товаром.
О
| Таблица CUSTOMERS | |
|
CUST_NUM |
COMPANY |
| … | |
|
2117 |
J.P. Sinclair |
| … |
| Таблица SALESREPS | |
|
EMPL_NUM |
NAME |
| … | |
|
106 |
Sam Clark |
| … |
| Таблица PRODUCTS | ||
|
MFR_ID |
PRODUCT_ID |
DESCRIPTION |
| … | ||
|
REI |
2A44L |
Left Hinge |
| … |
| Таблица ORDERS | |||||
|
ORDER_NUM |
ORDER_DATE |
CUST |
REP |
MFR |
PRODUCT |
| … | |||||
|
112967 |
17-DEC-89 |
2117 |
106 |
REI |
2A44L |
| … |


Рис. 1.9. Множественные отношения предок/потомок в реляционной базе данных
тношения предок/потомок, созданные с помощью трех внешних ключей в таблице ORDERS, могут показаться знакомыми. И действительно, это те же самые отношения, что и в сетевой базе данных, представленной на рис. 1.4. Как показывает пример, реляционная модель данных обладает всеми возможностями сетевой модели по части выражения сложных отношений.Внешние ключи являются неотъемлемой частью реляционной модели, поскольку реализуют отношения между таблицами базы данных. К несчастью, как и в случае с первичными ключами, поддержка внешних ключей отсутствовала в первых реляционных СУБД. Она была введена в системе DB2 Version 2 и теперь имеется во всех коммерческих СУБД.
Двенадцать правил Кодда
В статье, опубликованной в журнале "Computer World", Тэд Кодд сформулировал двенадцать правил, которым должна соответствовать настоящая реляционная база данных. Двенадцать правил Кодда приведены в табл. 1.1. Они являются полуофициальным определением понятия реляционная база данных. Перечисленные правила основаны на теоретической работе Кодда, посвященной реляционной модели данных.
|
Таблица 1.1. Двенадцать правил Кодда, которым должна соответствовать _ реляционная СУБД. _ |
|
1. Правило информации. Вся информация в базе данных должна быть предоставлена исключительно на логическом уровне и только одним способом - в виде значений, содержащихся в таблицах. |
|
2. Правило гарантированного доступа. Логический доступ ко всем и каждому элементу данных (атомарному значению) в реляционной базе данных должен обеспечиваться путём использования комбинации имени таблицы, первичного ключа и имени столбца. |
|
3. Правило поддержки недействительных значений. В настоящей реляционной базе данных должна быть реализована поддержка недействительных значений, которые отличаются от строки символов нулевой длинны, строки пробельных символов, и от нуля или любого другого числа и используются для представления отсутствующих данных независимо от типа этих данных. |
|
4. Правило динамического каталога, основанного на реляционной модели. Описание базы данных на логическом уровне должно быть представлено в том же виде, что и основные данные, чтобы пользователи, обладающие соответствующими правами, могли работать с ним с помощью того же реляционного языка, который они применяют для работы с основными данными. |
— определение
данных; |
|
6. Правило обновления представлений. Все представления, которые теоретически можно обновить, должны быть доступны для обновления. |
|
7. Правило добавления, обновления и удаления. Возможность работать с отношением как с одним операндом должна существовать не только при чтении данных, но и при добавлении, обновлении и удалении данных. |
|
8. Правило независимости физических данных. Прикладные программы и утилиты для работы с данными должны на логическом уровне оставаться нетронутыми при любых изменениях способов хранения данных или методов доступа к ним. |
|
9. Правило независимости логических данных. Прикладные программы и утилиты для работы с данными должны на логическом уровне оставаться нетронутыми при внесении в базовые таблицы любых изменений, которые теоретически позволяют сохранить нетронутыми содержащиеся в этих таблицах данные. |
|
10. Правило независимости условий целостности. Должна существовать возможность определять условия целостности, специфические для конкретной реляционной базы данных, на подъязыке реляционной базы данных и хранить их в каталоге, а не в прикладной программе. |
|
11. Правило независимости распространения. Реляционная СУБД не должна зависеть от потребностей конкретного клиента. |
|
12. Правило единственности. Если в реляционной системе есть низкоуровневой язык (обрабатывающий одну запись за один раз), то должна отсутствовать возможность использования его для того, чтобы обойти правила и условия целостности, выраженные на реляционном языке высокого уровня (обрабатывающем несколько записей за один раз). |
Правило 1 напоминает неформальное определение реляционной базы данных, приведенное ранее.
Правило 2 указывает на роль первичных ключей при поиске информации в базе данных. Имя таблицы позволяет найти требуемую таблицу, имя столбца позволяет найти требуемый столбец, а первичный ключ позволяет найти строку, содержащую искомый элемент данных.
Правило 3 требует, чтобы отсутствующие данные можно было представить с помощью недействительных значений (NULL), которые описаны в главе 5.
Правило 4 гласит, что реляционная база данных должна сама себя описывать. Другими словами, база данных должна содержать набор системных таблиц, описывающих структуру самой базы данных. Эти таблицы описаны в главе 16.
Правило 5 требует, чтобы СУБД использовала язык реляционной базы данных, например SQL, хотя явно SQL в правиле не упомянут. Такой язык должен поддерживать все основные функции СУБД — создание базы данных, чтение и ввод данных, реализацию защиты базы данных и т.д.
Правило 6 касается представлений, которые являются виртуальными таблицами, позволяющими показывать различным пользователям различные фрагменты структуры базы данных. Это одно из правил, которые сложнее всего реализовать на практике. Представления и проблемы их обновления описаны в главе 14.
Правило 7 акцентирует внимание на том, что базы данных по своей природе ориентированы на множества. Оно требует, чтобы операции добавления, удаления и обновления можно было выполнять над множествами строк. Это правило предназначено для того, чтобы запретить реализации, в которых поддерживаются только операции над одной строкой.
Правила 8 и 9 означают отделение пользователя и прикладной программы от низкоуровневой реализации базы данных. Они утверждают, что конкретные способы реализации хранения или доступа, используемые в СУБД, и даже изменения структуры таблиц базы данных не должны влиять на возможность пользователя работать с данными.
Правило 10 гласит, что язык базы данных должен поддерживать ограничительные условия, налагаемые на вводимые данные и действия, которые могут быть выполнены над данными.
Правило 11 гласит, что язык базы данных должен обеспечивать возможность работы с распределенными данными, расположенными на других компьютерных системах. Распределенные данные и проблемы управления ими описаны в главе 20.
И, наконец, правило 12 предотвращает использование других возможностей для работы с базой данных, помимо языка базы данных, поскольку это может нарушить ее целостность.
2. Язык SQL как стандартный язык баз данных.
Стремительный рост популярности SQL является одной из самых важных тенденций в современной компьютерной промышленности. За несколько последних лет SQL стал единственным языком баз данных. На сегодняшний день SQL поддерживают свыше ста СУБД, работающих как на персональных компьютерах, так и на больших ЭВМ. Был принят, а затем дополнен официальный международный стандарт на SQL. Язык SQL является важным звеном в архитектуре систем управления базами данных, выпускаемых всеми ведущими поставщиками программных продуктов, и служит стратегическим направлением разработок компании Microsoft в области баз данных. Зародившись в результате выполнения второстепенного исследовательского проекта компании IBM, SQL сегодня широко известен и в качестве мощного рыночного фактора.
Язык SQL
S
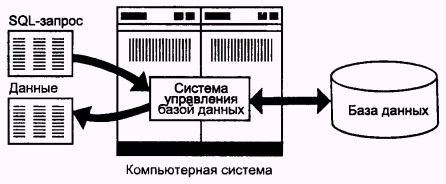
Рис. 2.1. Применение SQL для доступа к базе данных
QL является инструментом, предназначенным для обработки и чтения данных, содержащихся в компьютерной базе данных. SQL - это сокращенное название структурированного языка запросов (Structured Query Language). Как следует из названия, SQL является языком программирования, который применяется для организации взаимодействия пользователя с базой данных. На самом деле SQL работает только с базами данных одного определенного типа, называемых реляционными. На рис. 2.1 изображена схема работы SQL. Согласно этой схеме, в вычислительной системе имеется база данных, в которой хранится важная информация. Если вычислительная система относится к сфере бизнеса, то в базе данных может храниться информация о материальных ценностях, выпускаемой продукции, объемах продаж и зарплате. В базе данных на персональном компьютере может храниться информация о выписанных чеках, телефонах и адресах или информация, извлеченная из более крупной вычислительной системы. Компьютерная программа, которая управляет базой данных, называется системой управления базой данных, или СУБД.Если пользователю необходимо прочитать данные из базы данных, он запрашивает их у СУБД с помощью SQL. СУБД обрабатывает запрос, находит требуемые данные и посылает их пользователю. Процесс запрашивания данных и получения результата называется запросом к базе данных: отсюда и название — структурированный язык запросов.
Однако это название не совсем соответствует действительности. Во-первых, сегодня SQL представляет собой нечто гораздо большее, чем простой инструмент создания запросов, хотя именно для этого он и был первоначально предназначен. Несмотря на то, что чтение данных по-прежнему остается одной из наиболее важных функций SQL, сейчас этот язык используется для реализации всех функциональных возможностей, которые СУБД предоставляет пользователю, а именно:
Организация данных. SQL дает пользователю возможность изменять структуру представления данных, а также устанавливать отношения между элементами базы данных.
Чтение данных. SQL дает пользователю или приложению возможность читать из базы данных содержащиеся в ней данные и пользоваться ими.
Обработка ванных. SQL дает пользователю или приложению возможность изменять базу данных, т.е. добавлять в нее новые данные, а также удалять или обновлять уже имеющиеся в ней данные.
Управление доступом. С помощью SQL можно ограничить возможности пользователя по чтению и изменению данных и защитить их от несанкционированного доступа.
Совместное использование данных. SQL координирует совместное использование данных пользователями, работающими параллельно, чтобы они не мешали друг другу.
Целостность данных. SQL позволяет обеспечить целостность базы данных, защищая ее от разрушения из-за несогласованных изменений или отказа системы.
Таким образом, SQL является достаточно мощным языком для взаимодействия с СУБД.
Во-вторых, SQL — это не полноценный компьютерный язык типа COBOL, FORTRAN или С. В SQL нет оператора IF для проверки условий, нет оператора GOTO для организации переходов и нет операторов DO или FOR для создания циклов. SQL является подъязыком баз данных, в который входит около тридцати операторов, предназначенных для управления базами данных. Операторы SQL встраиваются в базовый язык, например COBOL, FORTRAN или С, и дают возможность получать доступ к базам данных. Кроме того, из такого языка, как С, операторы SQL можно посылать СУБД в явном виде, используя интерфейс вызовов функций.
Наконец, SQL — это слабо структурированный язык, особенно по сравнению с такими сильно структурированными языками, как С или Pascal. Операторы SQL напоминают английские предложения и содержат "слова-пустышки", не влияющие на смысл оператора, но облегчающие его чтение. В SQL почти нет нелогичностей, к тому же имеется ряд специальных правил, предотвращающих создание операторов SQL, которые выглядят как абсолютно правильные, но не имеют смысла.
Несмотря на не совсем точное название, SQL на сегодняшний день является единственным стандартным языком для работы с реляционными базами данных. SQL — это достаточно мощный и в то же время относительно легкий для изучения язык.
Роль SQL
Сам по себе SQL не является ни системой управления базами данных, ни отдельным программным продуктом. Нельзя пойти в компьютерный магазин и "купить SQL". SQL — это неотъемлемая часть СУБД, инструмент, с помощью которого осуществляется связь пользователя с ней. На рис. 2.2. изображена структурная схема типичной СУБД, компоненты которой соединяются в единое целое с помощью SQL (своего рода "клея").
Ядро базы данных является сердцевиной СУБД; оно отвечает за физическое структурирование и запись данных на диск, а также за физическое чтение данных с диска. Кроме того, оно принимает SQL-запросы от других компонентов СУБД (таких как генератор форм, генератор отчетов или модуль формирования интерактивных запросов), от пользовательских приложений и даже от других вычислительных систем. Как видно из рисунка, SQL выполняет много различных функций:
SQL — интерактивный язык запросов. Пользователи вводят команды SQL в интерактивные программы, предназначенные для чтения данных и отображения их на экране. Это удобный способ выполнения специальных запросов.
SQL — язык программирования баз данных. Чтобы получить доступ к базе данных, программисты вставляют в свои программы команды SQL. Эта методика используется как в программах, написанных пользователями, так и в служебных программах баз данных (таких как генераторы отчетов и инструменты ввода данных).
S
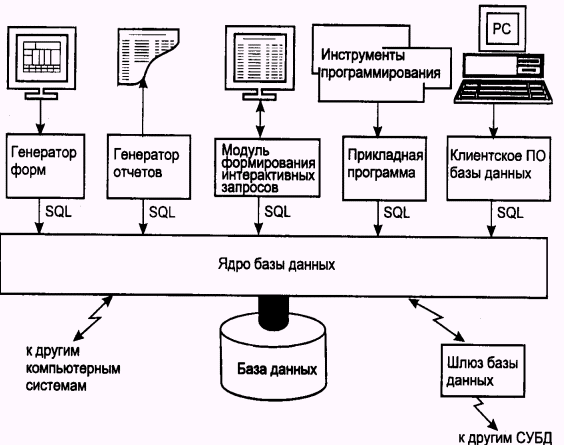
Рис. 2.2. Компоненты типичной СУБД
QL — язык администрирования баз данных. Администратор базы данных, находящейся на мини-компьютере или на большой ЭВМ, использует SQL для определения структуры базы данных и управления доступом к данным.SQL — язык создания приложений клиент/сервер, и программах для персональных компьютеров SQL используется для организации связи через локальную сеть с сервером базы данных, в которой хранятся совместно используемые данные. В большинстве новых приложений используется архитектура клиент/сервер, которая позволяет свести к минимуму сетевой трафик и повысить быстродействие как персональных компьютеров, так и серверов баз данных.
SQL — язык распределенных баз данных. В системах управления распределенными базами данных SQL помогает распределять данные среди нескольких взаимодействующих вычислительных систем. Программное обеспечение каждой системы посредством использования SQL связывается с другими системами, посылая им запросы на доступ к данным.
SQL — язык шлюзов базы данных. В вычислительных сетях с различными СУБД SQL часто используется в шлюзовой программе, которая позволяет СУБД одного типа связываться с СУБД другого типа.
Таким образом, SQL превратился в полезный и мощный инструмент, обеспечивающий людям, программам и вычислительным системам доступ к информации, содержащейся в реляционных базах данных.
Достоинства SQL
SQL — это легкий для понимания язык и в то же время универсальное программное средство управления данными.
Успех языку SQL принесли следующие его особенности:
• независимость от конкретных СУБД;
• переносимость с одной вычислительной системы на другую;
• наличие стандартов;
• одобрение компанией IBM (СУБД DB2);
• поддержка со стороны компании Microsoft (протокол ODBC);
• реляционная основа;
• высокоуровневая структура, напоминающая английский язык;
• возможность выполнения специальных интерактивных запросов:
• обеспечение программного доступа к базам данных;
• возможность различного представления данных;
• полноценность как языка, предназначенного для работы с базами данных;
• возможность динамического определения данных;
• поддержка архитектуры клиент/сервер.
Все перечисленные выше факторы явились причиной того, что SQL стал стандартным инструментом для управления данными на персональных компьютерах, мини-компьютерах и больших ЭВМ. Ниже эти факторы рассмотрены более подробно.
Независимость от конкретных СУБД
Все ведущие поставщики СУБД используют SQL, и ни одна новая СУБД, не поддерживающая SQL, не может рассчитывать на успех. Реляционную базу данных и программы, которые с ней работают, можно перенести с одной СУБД на другую с минимальными доработками и переподготовкой персонала. Программные средства, входящие в состав СУБД для персональных компьютеров, такие как программы для создания запросов, генераторы отчетов и генераторы приложений, работают с реляционными базами данных многих типов. Таким образом, SQL обеспечивает независимость от конкретных СУБД, что является одной из наиболее важных причин его популярности.
Переносимость с одной вычислительной системы на другие
Поставщики СУБД предлагают программные продукты для различных вычислительных систем: от персональных компьютеров и рабочих станций до локальных сетей, мини-компьютеров и больших ЭВМ. Приложения, созданные с помощью SQL и рассчитанные на однопользовательские системы, по мере своего развития могут быть перенесены в более крупные системы. Информация из корпоративных реляционных баз данных может быть загружена в базы данных отдельных подразделений или в личные базы данных. Наконец, приложения для реляционных баз данных можно вначале смоделировать на экономичных персональных компьютерах, а затем перенести на дорогие многопользовательские системы.
Стандарты языка SQL
Официальный стандарт языка SQL был опубликован Американским институтом национальных стандартов (American National Standards Institute — ANSI) и Международной организацией по стандартам (International Standards Organization — ISO) в 1986 году и значительно расширен в 1992 году. Кроме того, SQL является федеральным стандартом США по обработке информации (FIPS — Federal Information Processing Standard) и, следовательно, соответствие ему является одним из основных требований, содержащихся в больших правительственных контрактах, относящихся к области вычислительной техники. В Европе стандарт X/OPEN для переносимой среды программирования на основе операционной системы UNIX включает в себя SQL в качестве стандарта для доступа к базам данных. SQL Access Group — консорциум поставщиков компьютерного оборудования и баз данных — определил для SQL стандартный интерфейс вызовов функций, который является основой протокола ODBC компании Microsoft и входит также в стандарт X/OPEN. Эти стандарты служат как бы официальной печатью, одобряющей SQL, и они ускорили завоевание им рынка.
Одобрение SQL компанией IBM (СУБД DB2)
SQL был придуман научными сотрудниками компании IBM и широко используется ею во множестве пакетов программного обеспечения. Подтверждением этому служит флагманская СУБД DB2 компании IBM. Все основные семейства компьютеров компании IBM поддерживают SQL: система PS/2 для персональных компьютеров, система среднего уровня AS/400. система RS/6000 на базе UNIX, а также операционные системы MVS и VM больших ЭВМ. Широкая поддержка SQL фирмой IBM ускорила его признание и еще в самом начале возникновения и развития рынка баз данных явилась своего рода недвусмысленным указанием для других поставщиков баз данных и программных систем, в каком направлении необходимо двигаться.
Протокол ODBC и компания Microsoft
Компания Microsoft рассматривает доступ к базам данных как важную часть своей операционной системы Windows. Стандартом этой компании по обеспечению доступа к базам данных является ODBC (Open Database Connectivity — взаимодействие с открытыми базами данных) — программный интерфейс, основанный на SQL. Протокол ODBC поддерживается наиболее распространенными приложениями Windows (электронными таблицами, текстовыми процессорами, базами данных и т.п.), разработанными как самой компанией Microsoft, так и другими ведущими поставщиками. Поддержка ODBC обеспечивается всеми ведущими реляционными базами данных. Кроме того, ODBC опирается на стандарты, одобренные консорциумом поставщиков SQL Access Group, что делает ODBC как стандартом де-факто компании Microsoft, так и стандартом, независимым от конкретных СУБД.
Реляционная основа
SQL является языком реляционных баз данных, поэтому он стал популярным тогда, когда популярной стала реляционная модель представления данных. Табличная структура реляционной базы данных интуитивно понятна пользователям, поэтому язык SQL является простым и легким для изучения. Реляционная модель имеет солидный теоретический фундамент, на котором были основаны эволюция и реализация реляционных баз данных. На волне популярности, вызванной успехом реляционной модели, SQL стал единственным языком для реляционных баз данных.
Высокоуровневая структура,
напоминающая английский язык
Операторы SQL выглядят как обычные английские предложения, что упрощает их изучение и понимание. Частично это обусловлено тем, что операторы SQL описывают данные, которые необходимо получить, а не определяют способ их поиска. Таблицы и столбцы в реляционной базе данных могут иметь длинные описательные имена. В результате большинство операторов SQL означают именно то, что точно соответствует их именам, поэтому их можно читать как простые, понятные предложения.
Интерактивные запросы
SQL является языком интерактивных запросов, который обеспечивает пользователям немедленный доступ к данным. С помощью SQL пользователь может в интерактивном режиме получить ответы на самые сложные запросы в считанные минуты или секунды, тогда как программисту потребовались бы дни или недели, чтобы написать для пользователя соответствующую программу. Из-за того, что SQL допускает немедленные запросы, данные становятся более доступными и могут помочь в принятии решений, делая их более обоснованными.
Программный доступ к базе данных
Программисты пользуются языком SQL, чтобы писать приложения, в которых содержатся обращения к базам данных. Одни и те же операторы SQL используются как для интерактивного, так и для программного доступа, поэтому части программ, содержащие обращения к базе данных, можно вначале тестировать в интерактивном режиме, а затем встраивать в программу. В традиционных базах данных для программного доступа используются одни программные средства, а для выполнения немедленных запросов — другие, без какой либо связи между этими двумя режимами доступа.
Различные представления данных
С помощью SQL создатель базы может сделать так, что различные пользователи базы данных будут видеть различные представления её структуры и содержимого. Например, базу данных можно спроектировать таким образом, что каждый пользователь будет видеть только данные, относящиеся к его подразделению или торговому региону. Кроме того, данные из различных частей базы данных могут быть скомбинированы и представлены пользователю в виде одной простой таблицы. Следовательно, представления можно использовать для усиления защиты базы данных и ее настройки под конкретные требования отдельных пользователей.
Полноценный язык для работы с базами данных
Первоначально SQL был задуман как язык интерактивных запросов, но сейчас он вышел далеко за рамки чтения данных. SQL является полноценным и логичным языком, предназначенным для создания базы данных, управления ее защитой, изменения ее содержимого, чтения данных и совместного использования данных несколькими пользователями, работающими параллельно. Приемы, освоенные при изучении одного раздела языка, могут затем применяться в других командах, что повышает производительность работы пользователей.
Динамическое определение данных
С помощью SQL можно динамически изменять и расширять структуру базы данных даже в то время, когда пользователи обращаются к ее содержимому. Это большое преимущество перед языками статического определения данных, которые запрещают доступ к базе данных во время изменения ее структуры. Таким образом, SQL обеспечивает максимальную гибкость, так как дает базе данных возможность адаптироваться к изменяющимся требованиям, не прерывая работу приложения, выполняющегося в реальном масштабе времени.
Архитектура клиент/сервер
SQL — естественное средство для реализации приложений клиент/сервер. В этой роли SQL служит связующим звеном между клиентской системой, взаимодействующей с пользователем, и серверной системой, управляющей базой данных, позволяя каждой системе сосредоточиться на выполнении своих функций. Кроме того, SQL позволяет персональным компьютерам функционировать в качестве клиентов по отношению к сетевым серверам или более крупным базам данных, установленным на больших ЭВМ; это позволяет получать доступ к корпоративным данным из приложений, работающих на персональных компьютерах.
3. Стандарты SQL
Одним из наиболее важных шагов на пути к признанию SQL на рынке стало появление стандартов на этот язык. Обычно при упоминании стандарта SQL имеют в виду официальный стандарт, утвержденный Американским институтом национальных стандартов (American National Standards Institute — ANSI) и Международной организацией по стандартам (International Standards Organization— ISO). Однако существуют и другие важные стандарты SQL, включая SQL, реализованный в системе DB2 компании IBM, и стандарт X/OPEN для SQL в среде UNIX.
Стандарты ANSI/ISO
Работа над официальным стандартом SQL началась в 1982 году, когда ANSI поставил перед своим комитетом ХЗН2 задачу по созданию стандарта языка реляционных баз данных. Вначале в комитете обсуждались достоинства различных предложенных языков. Однако поскольку к тому времени SQL уже стал фактическим стандартом, комитет ХЗН2 остановил свой выбор на нем и занялся стандартизацией SQL.
Разработанный в результате стандарт в большой степени был основан на диалекте SQL системы DB/2, хотя и содержал в себе ряд существенных отличий от этого диалекта. После нескольких доработок, в 1986 году стандарт был официально утвержден как стандарт ANSI номер Х3.135, а в 1987 году — в качестве стандарта ISO. Затем стандарт ANSI/ISO был принят правительством США как федеральный стандарт США по обработке информации (FIPS — Federal Information Processing Standard). Этот стандарт, незначительно пересмотренный в 1989 году, обычно называют стандартом "SQL-89", ил"SQLI". Когда в данной книге упоминается "стандарт ANSI/ISO", то подразумевается SQLI, который в настоящее время лежит в основе большинства коммерческих продуктов.
Многие из членов комитетов по стандартизации ANSI и ISO представляли фирмы-поставщики различных СУБД, в каждой из которых был реализован собственный диалект SQL. Как и диалекты человеческого языка, диалекты SQL были в основном похожи друг на друга, однако несовместимы в деталях. Во многих случаях комитет просто обошел существующие различия и не стандартизировал некоторые части языка, определив, что они реализуются по усмотрению разработчика. Этот подход позволил объявить большое число реализаций SQL совместимыми со стандартом, однако сделал сам стандарт относительно слабым.
Чтобы заполнить эти пробелы, комитет ANSI продолжил свою работу и создал проект нового, более жесткого стандарта SQL2. В отличие от стандарта 1989 года, проект SQL2 предусматривал возможности, выходящие за рамки таковых, уже существующих в реальных коммерческих продуктах. А для следующего за ним стандарта SQL3 были предложены еще более глубокие изменения. В результате предложенные стандарты SQL2 и SQL3 оказались более противоречивыми, чем исходный стандарт. Стандарт SQL2 прошел процесс утверждения в ANSI и был окончательно принят в октябре 1992 года. В то время, как первый стандарт 1986 года занимает не более ста страниц, официальный стандарт SQL2 содержит около шестисот.
Вопреки стандарту SQL2, во всех существующих на сегодняшний день коммерческих продуктах поддерживаются собственные диалекты SQL. Более того, поставщики СУБД включают в свои продукты новые возможности и расширяют собственные диалекты SQL, чем еще больше отдаляют их от стандарта. Однако ядро SQL стандартизировано довольно жестко. Там, где это можно было сделать, не ущемляя интересы клиентов, поставщики СУБД привели свои продукты в соответствие со стандартом SQL-89, то же самое постепенно произойдет и с SQL2.
Другие стандарты SQL
Хотя стандарт ANSI/ISO наиболее широко распространен, он не является единственным стандартом SQL. Европейская группа поставщиков X/OPEN также приняла SQL в качестве одного из своих стандартов для "среды переносимых приложений" на основе UNIX. Стандарты группы X/OPEN играют важную роль на европейском компьютерном рынке, где основной проблемой является переносимость приложений между компьютерными системами различных производителей. К несчастью, стандарт X/OPEN отличается от стандарта ANSI/ISO.
Кроме того, компания IBM включила SQL в свою спецификацию Systems Application Architecture (архитектура прикладных систем) и пообещала, что все ее продукты, очевидно, будут переведены на этот диалект SQL. Хотя данная спецификация и не оправдала надежд на унификацию линии продуктов компании IBM, движение в сторону унификации SQL в IBM продолжается. Система DB2 остается основной СУБД компании IBM для мэйнфреймов. Однако компания выпустила реализацию DB2 и для OS/2собственной операционной системы для персональных компьютеров, и для линии серверов и рабочих станций RS/6000, работающих под управлением UNIX. Таким образом, диалект DB2 языка SQL является мощным стандартом де-факто.
ODBC u консорциум SQL Access Group
В технологии баз данных существует важная область, которую не затрагивают официальные стандарты. Это способность к взаимодействию с другими базами данных — методы, с помощью которых различные базы данных могут обмениваться данными (как правило, по сети). В 1989 году несколько поставщиков сформировали консорциум SQL Access Group специально для решения этой проблемы. В 1991 году консорциум опубликовал спецификацию RDA (Remote Database Access — удаленный доступ к базам данных). К несчастью, эта спецификация тесно связана с протоколами OSI, которые не смогли завоевать широкого признания, поэтому она оказывает на рынок незначительное влияние. Прозрачность взаимодействия между различными базами данных остается иллюзорной мечтой.
Тем не менее,
второй стандарт
от SQL Access
Group имеет
на рынке больший
вес. В результате
настойчивых
требований
компании
Microsoft, консорциум
SQL Access Group включил
в стандарт
SQL интерфейс
вызовов функций.
Полученная
спецификация
CLI (Call Level Interface), основанная
на разработках
компании
Microsoft, увидела
свет в
1992 году. В
этом же году
была
опубликована
собственная
спецификация
ODBC (Open Database Connectivity
— взаимодействие
с открытыми
базами данных)
компании
Microsoft, основанная
на стандарте
CLI. Благодаря
рыночной силе
Microsoft и благословению,
полученному
"открытым
стандартом"
от SQL Access
Group, ODBC оказался
стандартом
де-факто для
интерфейсов
доступа к базам
данных на
персональных
компьютерах.
Весной
1993 года компании
Apple и Microsoft
объявили о
соглашении
относительно
поддержки
ODBC в
MacOS и
Windows, что закрепило
за этой спецификацией
статус стандарта
в обеих популярных
средах с графическим
пользовательским
интерфейсом.
Миф о переносимости
Появление стандарта SQL вызвало довольно много восторженных заявлений о переносимости SQL и использующих его приложений. Для иллюстрации того, как любое приложение, используя SQL, может работать с любой СУБД, часто приводят диаграммы, подобные изображенной на рис. 3.1. На самом деле пробелы в стандарте SQL-89 и различия между существующими диалектами SQL достаточно значительны, и при переводе приложения под другую СУБД его всегда приходится модифицировать. Эти отличия, большинство из которых устранено в стандарте SQL2, включают в себя:
Коды ошибок. В стандарте SQL-89 не определены коды, которые возвращают операторы SQL при возникновении ошибок, и в каждой из коммерческих реализаций используется собственный набор таких кодов. В стандарте SQL2 определены стандартные коды ошибок.
Типы данных. В стандарте SQL-89 определен минимальный набор типов данных, однако в нем отсутствуют некоторые из наиболее распространенных и полезных типов, например символьные строки переменной длины, дата и время, а также денежные единицы. В стандарте SQL2 упомянуты эти типы данных, однако отсутствуют "новые" типы данных, такие как графические и мультимедийные объекты.
Системные таблицы. В стандарте SQL-89 умалчивается о системных таблицах, в которых содержится информация о структуре самой базы данных. Поэтому каждый поставщик создавал собственные системные таблицы, и их структура отличается даже в четырех реализациях SQL компании IBM. Системные таблицы стандартизированы в SQL2.
Интерактивный SQL. В стандарте определен только программный SQL, используемый прикладной программой, но не интерактивный SQL. Например, оператор select, предназначенный для выполнения запросов к базе данных в интерактивном режиме, в стандарте отсутствует.
Программный интерфейс. В первом стандарте определен абстрактный способ использования SQL в программах, написанных на таких языках программирования, как COBOL, FORTRAN и другие. Этот способ не используется ни в одном коммерческом продукте, а в существующих программных интерфейсах имеются значительные отличия. В стандарте SQL2 определен интерфейс встроенного SQL для популярных языков программирования, но не интерфейс вызова функций.
Динамический SQL. В стандарте SQL-89 не описаны элементы SQL, необходимые для разработки приложений общего назначения, таких как генераторы отчетов и программы создания и выполнения запросов. Однако эти элементы, известные под названием динамический SQL, имеются почти во всех СУБД и в различных системах значительно отличаются. В SQL2 входит стандарт динамического SQL.
Семантические отличия. Поскольку некоторые элементы определены в стандартах как зависящие от реализации, может возникнуть ситуация, когда в результате выполнения одного и того же запроса в двух совместимых СУБД будут получены два различных набора результатов. Отличия результатов обусловлены различиями в обработке значений null, разными агрегатными функциями и несовпадением процедур удаления повторяющихся строк.
Последовательность сравнения. В стандарте SQL-89 не упоминаются последовательности сравнения (сортировки) символов, хранящихся в базе данных. Результаты запроса с сортировкой будут отличаться при выполнении этого запроса на персональном компьютере (с кодировкой ASCII) и на мэйнфрейме (с кодировкой EBCDIC). Стандарт SQL2 позволяет программе или пользователю указывать требуемую последовательность сортировки.
С

Приложение # 1
Приложение # 2
Приложение # 3
Приложение # 4
Стандарт SQL


СУБД # 1
СУБД # 2
СУБД # 3
Рис. 3.1. Миф о переносимости SQL
труктура базы данных. В стандарте SQL-89 определен SQL, который используется уже после того, как база данных была открыта и подготовлена к работе. Детали наименования баз данных и первоначального подключения к ним сильно отличаются и несовместимы. Стандарт SQL2 в некоторой степени унифицирует этот процесс, но не может полностью ликвидировать все отличия.
Вопреки перечисленным различиям, в начале 90-х годов стали появляться коммерческие программы, реализующие переносимость приложений между различными СУБД, Однако в таких программах для каждой из поддерживаемых СУБД требуется специальный конвертер, который генерирует код в соответствии с определенным диалектом SQL, выполняет преобразование- типов данных, транслирует коды ошибок и т.д. "Прозрачная" переносимость между различными СУБД, использующими SQL, является основной целью стандарта SQL2 и протокола ODBC, однако повсеместный, "прозрачный" и унифицированный доступ к базам данных SQL остается делом будущего.
4. Влияние SQL
Будучи стандартным языком доступа к реляционной базе данных, SQL оказывает большое влияние на все сегменты компьютерного рынка. Компания IBM приняла SQL в качестве унифицирующей технологии баз данных для линии своих продуктов. Все поставщики мини-компьютеров предлагают реляционные базы данных; такие базы данных доминируют и на рынке компьютерных систем, работающих под управлением UNIX. По мере того как отдельные персональные компьютеры уступают дорогу сетям с архитектурой клиент/сервер, SQL видоизменяет рынок баз данных для персональных компьютеров. SQL применяется даже при оперативной обработке транзакций, опровергая бытовавшее ранее мнение, что из-за низкого быстродействия реляционные базы данных никогда не смогут использоваться в приложениях для обработки транзакций.
SQL и спецификация SAA компании IBM
SQL играет ключевую роль в качестве языка доступа к базам данных, объединяющего многочисленные несовместимые компьютерные семейства компании IBM. Эта роль была отведена ему еще в спецификации SAA (Systems Application Architecture — архитектура прикладных систем) компании IBM в 1987 году. Хотя главные цели SAA так и не были достигнуты, объединяющая роль SQL со временем стала еще важнее. Стратегическими программными продуктами компании IBM, предназначенными для работы с базами данных, являются
DB2. Флагманская реляционная СУБД, являющаяся стандартом SQL для мэйнфреймов компании IBM, работающих под управлением ОС MVS.
SQL/DS. Реляционная СУБД для VM, другой ОС мэйнфреймов компании IBM.
SQL/400. Эта реализация SQL для систем среднего уровня поддерживает встроенную реляционную базу данных компьютеров серии AS/400.
DB2/6000. Эта реализация DB2 работает на рабочих станциях и серверах семейства RS/6000, работающих под управлением операционной системы UNIX.
DB2/2. Эта реализация SQL для персональных компьютеров компании IBM основана на реализации DB2 для мэйнфреймов. Она заменила OS/2 Extended Edition, которая была первой реляционной СУБД компании IBM для персональных компьютеров, и обеспечила лучшую совместимость с DB2.
SQL на мини-компьютерах
Сегмент рынка реляционных СУБД для мини-компьютеров начал развиваться одним из первых. Первые продукты компаний Oracle и Ingres предназначались для мини-компьютеров VAX/VMS компании Digital. С тех пор оба продукта были перенесены на множество других платформ. СУБД компании Sybase, появившаяся позднее и предназначенная для оперативной обработки транзакций, работала на нескольких платформах, включая VAX.
Кроме того, поставщики мини-компьютеров разрабатывали на основе SQL собственные реляционные базы данных. Компания Digital на каждую систему VAX/VMS устанавливала собственную СУБД Rdb/VMS. Компания Hewlett-Packard предложила Allbase, СУБД, поддерживающую как собственный диалект HPSQL, так и нереляционный интерфейс. Компания Data General заменила свои старые нереляционные базы данных на СУБД DG/SQL. К тому же многие из поставщиков мини-компьютеров перепродают реляционные СУБД независимых поставщиков.
SQL на сиcтемах UNIX
SQL был однозначно признан лучшим решением в области управления данными для компьютерных систем на основе UNIX. Операционная система UNIX, которая была разработана в Bell Laboratories, в 80-х годах стала завоевывать популярность в качестве стандартной операционной системы. Она работает на разнообразных компьютерных системах, начиная от рабочих станций и заканчивая мэйнфреймами, и стала стандартной ОС для научных и инженерных приложений. В начале 80-х уже были доступны четыре большие СУБД для UNIX-систем. Две из них, производства компаний Oracle и Ingres, были UNIX-версиями продуктов для мини-компьютеров компании DEC, Две другие СУБД, производства компаний Informix и Unify, были созданы специально для UNIX. Вначале ни одна из них не предлагала поддержку SQL, но к 1985 году компании Unify и Informix ввели эту поддержку в свои СУБД. На сегодняшний день существуют версии СУБД компаний Oracle, Sybase, Informix и Ingres для всех ведущих систем на базе UNIX.
SQL и обработка транзакций
В процессе своего развития SQL и реляционные базы данных почти не применялись в приложениях, предназначенных для оперативной обработки транзакций (OLTP — On-Line Transaction Processing). Поскольку в реляционных базах данных упор делается на запросы, такие базы данных традиционно использовались в приложениях, служащих для поддержки принятия решений, и приложениях с маленьким объемом транзакций, где их низкое быстродействие не было недостатком. В области оперативной обработки транзакций, где требовалось обеспечить одновременный доступ к данным сотням пользователей, и время ожидания каждого из них не должно было превышать доли секунды, доминировала нереляционная СУБД IMS (Information Management System — система управления информацией) компании IBM.
В 1986 году компания Sybase, новая на рынке СУБД, представила реляционную базу данных, предназначенную специально для оперативной обработки транзакций. СУБД компании Sybase работала на мини-компьютерах VAX и рабочих станциях Sun и обеспечивала уровень быстродействия, необходимый для обработки больших объемов транзакций. Вскоре вслед за нею компании Oracle Corporation и Relational Technology объявили, что они также выпустят версии своих продуктов Oracle и Ingres для оперативной обработки транзакций. На рынке UNIX-систем компания Informix анонсировала OLTP-версию своей СУБД под названием Informix-Turbo.
В апреле 1988 года компания IBM присоединилась к поставщикам реляционных СУБД для OLTP, выпустив систему DB2 Version 2. Тесты показали, что на больших мэйнфреймах эта система могла обрабатывать до 250 транзакций в секунду. Компания IBM утверждала, что теперь быстродействие DB2 позволяет использовать ее во всех OLTP-приложениях, кроме наиболее требовательных к быстродействию, и поощряла клиентов использовать ее вместо IMS. После этого тесты стали стандартным маркетинговым инструментом для реляционных СУБД, вопреки серьезным сомнениям в том, насколько они отражают быстродействие реальных приложений.
По мере развития реляционной технологии и увеличения мощности компьютеров роль SQL в оперативной обработке транзакций также возрастает. Теперь для оперативной обработки транзакций часто используются реляционные базы данных, быстродействие которых выросло на несколько порядков.
SQL на персональных компьютерах
С появлением первой модели IBM PC базы данных стали приобретать популярность на рынке персональных компьютеров. СУБД dBASE компании Ashton-Tate была инсталлирована более чем на миллионе PC, работавших под управлением MS-DOS; другие продукты, такие как R-BASE, PFS: File и Paradox, также достигли значительного успеха. На компьютерах семейства Macintosh такие СУБД, как 4th Dimension, объединили в себе управление данными и графический интерфейс пользователя. Хотя в большинстве СУБД для персональных компьютеров данные хранились в табличной форме, эти СУБД не обладали полной мощью реляционной базы данных и не поддерживали SQL.
До конца 80-х SQL мало использовался на персональных компьютерах. К тому времени обычным явлением стали персональные компьютеры, поддерживающие дисковые устройства объемом в десятки и сотни мегабайтов. Однако вскоре пользователи начали объединять персональные компьютеры в сети, и появилась необходимость в совместном использовании данных. В результате персональные компьютеры стали нуждаться в возможностях, которые могли обеспечить реляционные базы данных и SQL.
Первые СУБД для персональных компьютеров представляли собой соответствующим образом переработанные версии известных СУБД для миникомпьютеров и с трудом умещались на персональных компьютерах. Система Professional Oracle, анонсированная в 1984 году, требовала двух мегабайтов памяти на IBM PC, a Oracle for Macintosh, представленная в 1988 году, имела схожие требования. Версия СУБД Ingres для PC, выпущенная в 1984 году, едва удовлетворяла ограничению MS-DOS на объем используемой оперативной памяти (640 Кб). СУБД Informix-SQL для MS-DOS была выпущена в 1986 году и представляла собой версию популярной СУБД, работавшей под управлением UNIX. В том же 1986 году компания Gupta Technologies, основанная бывшим менеджером из Oracle, выпустила SQLBase, СУБД для локальных сетей, которая одной из первых реализовала архитектуру клиент/сервер и была прототипом нынешних СУБД для ЛВС.
С появлением в апреле 1987 года операционной системы OS/2, созданной компаниями Microsoft и IBM, начался рост популярности SQL применительно к персональным компьютерам. Кроме стандартной версии OS/2, компания IBM выпустила расширенную редакцию OS/2 (OS/2 Extended Edition — OS/2 ЕЕ) со встроенной поддержкой реляционных баз данных. Сделав SQL частью операционной системы, компания IBM тем самым вновь подтвердила свою приверженность ему.
Появление OS/2 ЕЕ стало проблемой для компании Microsoft. Поскольку она была разработчиком стандартной OS/2 и продавала ее другим производителям персональных компьютеров, потребовалась альтернатива OS/2 ЕЕ. Ответом Microsoft стала покупка лицензии на СУБД компании Sybase, разработанной для VAX, и перенос этой СУБД в систему OS/2.
В январе
1988 года
Microsoft и
Ashton-Tate неожиданно
объявили, что
они будут совместно
продавать новую
СУБД, получившую
название
SQL Server. Компания
Microsoft будет
продавать
SQL Server вместе
с OS/2 производителям
компьютеров,
а компания
Ashton-Tate будет
продавать
SQL Server по розничным
каналам пользователям
PC. В сентябре
1989 года
компания
Lotus Development внесла
свой вклад в
SQL Server, сделав
инвестицию
в компанию
Sybase. Через
год с небольшим
компания
Ashton-Tate отказалась
от исключительных
прав на распространение
и продала свою
долю компании
Lotus. Хотя успех
SQL Server для
OS/2 был
ограниченным,
она
продолжает
играть ключевую
роль в планах
компании
Microsoft. Эта СУБД
является реляционной
базой данных
для Windows
NT, флагманской
операционной
системы компании
Microsoft, предназначенной
для работы в
среде клиент/сервер.
SQL в локальных сетях
Появление OS/2 Extended Edition и SQL Server привлекло внимание к потенциальным возможностям SQL в локальных вычислительных сетях. Заказчики стали всерьез рассматривать архитектуру клиент/сервер в качестве альтернативы центральному мини-компьютеру или мэйнфрейму.
Вначале на рынке SQL для ЛВС в качестве платформы для сервера баз данных доминировала OS/2. В отличие от MS-DOS, у этой операционной системы не было ограничения на объем ОЗУ (640 Кб), а ее многозадачная архитектура хорошо подходила для создания сервера баз данных. К концу 1989 года компании IBM, Microsoft, Oracle, Gupta и другие представили свои СУБД для OS/2. Однако объемы продаж OS/2 оказались меньше ожидаемых, в то время как объемы продаж Microsoft Windows 3.0 возросли. Вопреки всем попыткам подчеркнуть их различия, между OS/2 и Windows 3.0 возникла конкуренция, которая постепенно привела к разрыву между IBM и Microsoft. В конце концов компания Microsoft признала свою приверженность Windows 3.0 и отказалась от поддержки OS/2, оставив за нею статус "собственности IBM". Хотя OS/2 продолжает занимать важное место в планах компании IBM, ее шанс стать доминирующей промышленной операционной системой для персональных компьютеров — а значит, и наиболее подходящей платформой для SQL в ЛВС — упущен.
В то время
как шла борьба
между
OS/2 и
Windows, стали
расти объемы
продаж реляционных
баз данных для
других сетевых
платформ. Цены
на компьютеры,
работающие
под управлением
UNIX, постоянно
снижались, а
версия
UNIX от компании
Santa Cruz Operation (SCO UNIX) стала
наиболее популярной
платформой
для персональных
компьютеров
на базе процессоров
Intel. В начале
90-х годов
SCO UNIX могла
поддерживать
несколько
процессоров,
что позволило
делить загрузку
компьютера
между двумя,
тремя или более
микропроцессорами.
Имея в своем
распоряжении
вычислительную
мощь четырех-восьми
процессоров,
работающих
параллельно,
СУБД
Oracle, Informix и
Sybase смогли
достичь быстродействия
мини-компьютеров
на
серверах
семейства
PC стоимостью
от $20000.
На сегодняшний
день многопроцессорные
серверы от
компаний
Compaq, Dell, IBM и других
поставщиков
персональных
компьютеров
имеют наилучшее
соотношение
цена/производительность
среди всех
доступных на
рынке компьютерных
систем.
Хотя UNIX стала популярной платформой для серверов баз данных, подавляющее большинство серверов ЛВС все еще применяются только для совместного использования файлов и принтеров, и большинство этих серверов работают под управлением Novell Netware. Серверная операционная система Novell Netware реализует меньшие возможности, чем UNIX или OS/2, но у нее есть одно большое преимущество — объем продаж. Первые реляционные базы данных для Netware котировались хуже, чем СУБД для UNIX и OS/2, однако начиная с 1992 года все ведущие поставщики баз данных представили версии своих продуктов для Netware. Объемы Продаж этих продуктов стали быстро расти, и Netware оказалась жизнеспособной платформой для серверов баз данных.
В противоборстве с UNIX, OS/2 и Netware компания Microsoft сделала упор на Windows NT, клиент/серверную платформу для ЛВС, У Windows NT есть ряд значительных преимуществ над конкурентами; это новая операционная система, не отягощенная "обратной совместимостью". Учитывая вес компании Microsoft на компьютерном рынке, большинство аналитиков полагает, что NT завоюет лидирующее положение в области сетей с архитектурой клиент/сервер. В результате все поставщики СУБД в настоящее время выпускают версии своих продуктов для работы под управлением Windows NT.
Сегодня рынок СУБД для сетей с архитектурой клиент/сервер является наиболее быстро растущим сегментом рынка серверов ЛВС.
