

 Реферат: Процессор AMD. История развития
Реферат: Процессор AMD. История развития
Кеш
Прежде чем переходить непосредственно к функционированию AMD Athlon, хочется затронуть тему L1 и L2 кешей.
Что касается кеша L1 в AMD Athlon, то его размер 128 Кбайт превосходит размер L1 кеша в Intel Pentium III аж в 4 раза, не только подкрепляя высокую производительность Athlon, но и обеспечивая его эффективную работу на высоких частотах. В частности, одна из проблем используемой Intel архитектуры Katmai, которая, похоже, уже не позволяет наращивать быстродействие простым увеличением тактовой частоты, как раз заключается в малом объеме L1 кеша, который начинает захлебываться при частотах, приближающихся к гигагерцу. AMD Athlon лишен этого недостатка.
Что же касается кеша L2, то и тут AMD оказалось на высоте. Во-первых, интегрированный в ядро tag для L2-кеша поддерживает его размеры от 512 Кбайт до 16 Мбайт. Pentium III, как известно, имеет внешнюю Tag-RAM, подерживающую только 512-килобайтный кеш второго уровня. К тому же, Athlon может использовать различные делители для скорости L2-кеша: 1:1, 1:2, 2:3 и 1:3. Такое разнообразие делителей позволяет AMD не зависеть от поставщиков SRAM определенной скорости, особенно при выпуске более быстрых моделей.
Благодаря возможности варьировать размеры и скорости кеша второго уровня AMD собирается выпускать четыре семейства процессоров Athlon, ориентированных на разные рынки.
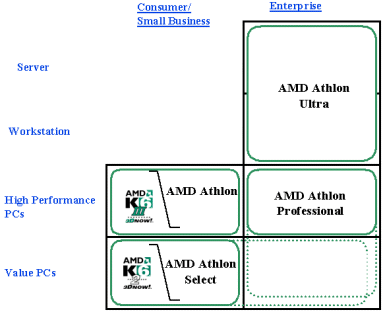
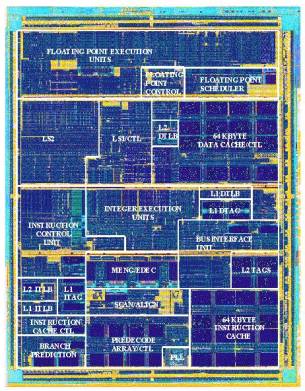 Архитектура.
Общие положения
Архитектура.
Общие положения
Вот мы и подошли к рассказу о том, как же, собственно, работает Athlon. Как и процессоры от Intel с ядром, унаследованным от Pentium Pro, процессоры Athlon имеют внутреннюю RISC-архитектуру. Это означает, что все CISC-команды, обрабатываемые процессором, сначала раскладываются на простые RISC-операции, а потом только начинают обрабатываться в вычислительных устройствах CPU. Казалось бы, зачем усложнять себе жизнь? Оказывается, есть зачем. Сравнительно простые RISC-инструкции могут выполняться процессором по несколько штук одновременно и намного облегчают предсказание переходов, тем самым позволяя наращивать производительность за счет большего параллелизма. Говоря более просто, тот производитель, который сделает более "параллельный" процессор, имеет шанс добиться превосходства в производительности гораздо меньшими усилиями. AMD при проектировании Athlon, по-видимому, руководствовалась и этим принципом.
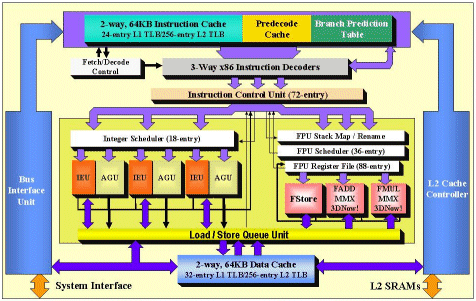 Однако перед
тем, как начать работу над параллельными потоками инструкций, процессор должен
их откуда-то получить. Для этого в AMD Athlon, как впрочем и в Intel Pentium
III, применяется дешифратор команд (декодер), который преобразует поступающий
на вход процессора код. Дешифратор в AMD Athlon может раскладывать на
RISC-составляющие до трех входящих CISC-команд одновременно. Современные
интеловские процессоры могут также обрабатывать до трех команд, однако если для
Athlon совершенно все равно, какие команды он расщепляет, Pentium III хочет,
чтобы две из трех инструкций были простыми и только одна - сложной. Это
приводит к тому, что если Athlon за каждый процессорный такт может переварить
три инструкции независимо ни от чего, то у Pentium III отдельные части
дешифратора могут простаивать из-за неоптимизированного кода.
Однако перед
тем, как начать работу над параллельными потоками инструкций, процессор должен
их откуда-то получить. Для этого в AMD Athlon, как впрочем и в Intel Pentium
III, применяется дешифратор команд (декодер), который преобразует поступающий
на вход процессора код. Дешифратор в AMD Athlon может раскладывать на
RISC-составляющие до трех входящих CISC-команд одновременно. Современные
интеловские процессоры могут также обрабатывать до трех команд, однако если для
Athlon совершенно все равно, какие команды он расщепляет, Pentium III хочет,
чтобы две из трех инструкций были простыми и только одна - сложной. Это
приводит к тому, что если Athlon за каждый процессорный такт может переварить
три инструкции независимо ни от чего, то у Pentium III отдельные части
дешифратора могут простаивать из-за неоптимизированного кода.
Перед тем, как попасть в соответствующий вычислительный блок, поступающий поток RISC-команд задерживается в небольшом буфере (Instruction Control Unit), который, что уже неудивительно, у AMD Athlon расчитан на 72 инструкции против 20 у Pentium III. Увеличивая этот буфер, AMD попыталась добиться того, чтобы дешифратор команд не простаивал из-за переполнения Instruction Control Unit.
Еще один момент, заслуживающий внимания - вчетверо большая, чем у Pentium III, таблица предсказания переходов размером 2048 ячеек, в которой сохраняются предыдущие результаты выполнения логических операций. На основании этих данных процессор прогнозирует их результаты при их повторном выполнении. Благодаря этой технике AMD Athlon правильно предсказывает результаты ветвлений где-то в 95% случаев, что очень даже неплохо, если учесть, что аналогичная характеристика у Intel Pentium III всего 90%.
Посмотрим теперь, что же происходит в Athlon, когда дело доходит непосредственно до вычислений.
Целочисленные операции
С целочисленными операциями у процессоров от AMD всегда все было в порядке. Со времен AMD K6 процессоры от Intel проигрывали именно в скорости целочисленных вычислений. Тем не менее, в Athlon AMD напрочь отказалась от старого наследия.
Благодаря наличию трех конвейерных блоков исполнения целочисленных команд (Integer Execution Unit) AMD Athlon может выполнять три целочисленные инструкции одновременно. Что же касается Pentium III, то его возможности ограничиваются одновременным выполнением только двух команд.
Отдельно хочется затронуть вопрос конвейеров. Оптимальной глубиной конвейера для процессоров с современными скоростями считается 9 стадий. Увеличение этого числа приводит к ускорению процесса обработки команд, так как скорость работы конвейера определяется работой самой медленной его стадии. Однако, в случае слишком большого конвейера при ошибках в предсказании переходов оказывается что большая часть работы по исполнению команд, уже вошедших на конвейер выполнена напрасно. Его приходится очищать и начинать процесс заново.
Потому в AMD Athlon глубина целочисленных конвейеров составляет 10 стадий, что близко к оптимуму. К сожалению, поклонники продукции Intel снова не услышат ничего утешительного, так как конвейер в Pentium III состоит из 12-17 стадий в зависимости от типа исполняемой инструкции.
Вещественные операции
С замиранием сердца обращаем наш взгляд на блок FPU, встроенный в Athlon. Как мы все хорошо помним, для предыдущих процессоров AMD операции с плавающей точкой были настоящей ахиллесовой пятой. Главной проблемой было то, что блок FPU в K6, K6-2 и K6-III был неконвейеризированый. Это приводило к тому, что хотя многие операции с плавающей точкой в FPU от AMD выполнялись за меньшее число тактов, чем на интеловских процессорах, общая производительность была катастрофически низкой, так как следующая вещественная операция не могла начать выполняться до завершения предыдущей. А что-то менять в своем FPU AMD в то время не хотела, призывая разработчиков к отказу от его использования в пользу 3DNow!.
Но, похоже, прошлый опыт научил AMD. В Athlon арифметический сопроцессор имеет конвейер глубиной 15 стадий против 25 у Pentium III. Не следует забывать, что, как уже говорилось выше, более длинный конвейер не всегда обеспечивает лучшую производительность. К тому же, существенным недостатком Intel Pentium III, которого в Athlon, естественно нет, является неконвейерезируемость операций FMUL и FDIV.
FPU в Athlon объединяет в себе три блока: один для выполнения простых операций типа сложения, второй - для сложных операций типа умножения и третий - для операций с данными. Благодаря такому разделению работы Athlon может выполнять одновременно по две вещественночисленные инструкциии. А ведь такого не умеет даже Intel Pentium III - он выполняет инструкции только последовательно!
Так что, как это ни странно, FPU интеловских процессоров оказался не таким уж замечательным, как это принято было считать ранее.
MMX
На первый взгляд с выполнением MMX-операций у Athlon по сравнению с K6-III изменений не произошло. Однако это не совсем так. Хотя и MMX-инструкции используются в крайне небольшом числе приложений, AMD добавила в этот набор еще несколько инструкций, которые также появились в MMX-блоке процессора Pentium III. В их число вошли нахождение среднего, максимума и минимума и изощренные пересылки данных.
Если обратить внимание на архитектурные особенности, то в AMD Athlon имеется по два блока MMX, потому на обоих процессорах - и на Athlon, и на Pentium III - может выполняться одновременно пара MMX-инструкций. Однако, MMX-блоки в AMD Athlon имеют большую, чем у Pentium III латентность, что теоретически должно приводить к отставанию этого CPU в MMX-приложениях.
3DNow!
Блока 3DNow! в AMD Athlon коснулись сильные изменения. Хотя его архитектура и осталась неизменной - два конвейера обрабатывают инструкции, работающие с 64-битными регистрами, в которых лежат пары вещественных чисел одинарной точности, в сам набор команд было добавлено 24 новинки. Новые операции должны не только позволить увеличить скорость обработки данных, но и позволить задействовать технологию 3DNow! в таких областях, как распознавание звука и видео, а также интернет :) Кроме этого, по аналогии с SSE были добавлены и инструкции для работы с данными, находящимися в кеше. Поддержка обновленного набора 3DNow! уже встроена в Windows 98 SE и в DirectX 6.2.
Таким образом, в набор 3DNow! входит теперь 45 команд, против 71 инструкции в SSE от Intel. Причем, судя по всему, использование новых команд должно дать еще больший эффект от 3DNow! В доказательство этого факта AMD распространила дополнительный DLL для известного теста 3DMark 99 MAX, задействующий новые возможности процессора.
Специально для оценки эффективности процессора в 3D-играх, 3DMark 99 MAX предлагает индекс CPU 3DМark, просчитывающий 3D-сцены, но не выводящий их не экран. Таким образом, получается результат, зависящий только от возможностей процессора по обработке 3D-графики и от пропускной способности основной памяти.
Чипсеты
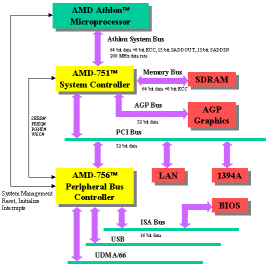 Прекратив разрабатывать
процессоры под гнездо Super 7 и начав продвигать собственный Slot A и системную
шину EV6, AMD оказалась отрезана от всех интеловских наработок на поприще
чипсетов и системных плат. Теперь AMD придется самой создавать необходимую
инфраструктуру, чтобы мы могли приобрести не только процессор, но и системную
плату, оборудованную Slot A.
Прекратив разрабатывать
процессоры под гнездо Super 7 и начав продвигать собственный Slot A и системную
шину EV6, AMD оказалась отрезана от всех интеловских наработок на поприще
чипсетов и системных плат. Теперь AMD придется самой создавать необходимую
инфраструктуру, чтобы мы могли приобрести не только процессор, но и системную
плату, оборудованную Slot A.
