

 Реферат: Организация Web-доступа к базам данных с использованием SQL-запросов
Реферат: Организация Web-доступа к базам данных с использованием SQL-запросов
WWW – доступ к существующим базам данных может осуществляться по одному из трех основных сценариев. Ниже дается их краткое описание и основные характеристики.
Однократное или периодическое преобразование содержимого БД в статические документы
В этом варианте содержимое БД просматривает специальная программа, создающая множество файлов – связных HTML-документов (см.рис.2.14 ).
Полученные файлы могут быть перенесены на один или несколько WWW-серверов. Доступ к ним будет осуществляться как к статическим гипертекстовым документам сервера.
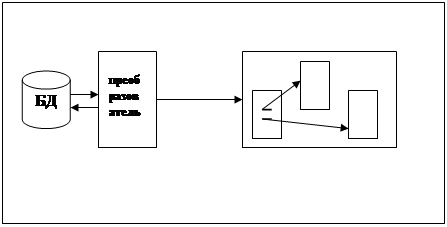 |
Рисунок 2.14
Этот вариант характеризуется минимальными начальными расходами. Он эффективен на небольших массивах данных простой структуры и редким обновлением, а также при пониженных требованиях к актуальности данных, предоставляемых через WWW. Кроме этого, очевидно полное отсутствие механизма поиска, хотя возможно развитое индексирование.
В качестве преобразователя может выступать программный комплекс, автоматически или полуавтоматически генерирующий статические документы. Программа-преобразователь может являться самостоятельно разработанной программой либо быть интегрированным средством класса генераторов отчетов.
Динамическое создание гипертекстовых документов на основе содержимого БД
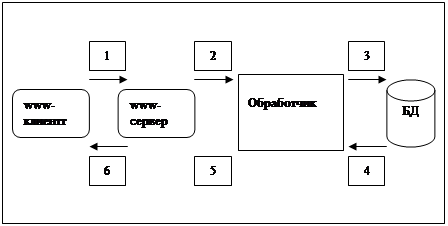 |
В этом варианте доступ к БД осуществляется специальной CGI-программой, запускаемой WWW-сервером в ответ на запрос WWW – клиента. Эта программа, обрабатывая запрос, просматривает содержимое БД и создает выходной HTML-документ, возвращаемый клиенту (см.рис.2.15).
Рисунок 2.15
Это решение эффективно для больших баз данных со сложной структурой и при необходимости поддержки операций поиска. Показаниями также являются частое обновление и невозможность синхронизации преобразования БД в статические документы с обновлением содержимого. В этом варианте возможно осуществлять изменение БД из WWW-интерфейсов.
К недостаткам этого метода можно отнести большое время обработки запросов, необходимость постоянного доступа к основной базе данных, дополнительную загрузку средств поддержки БД, связанную с обработкой запросов от WWW – сервера.
Для реализации такой технологии необходимо использовать взаимодействие WWW-сервера с запускаемыми программами CGI – Common Gateway Interface. Выбор программных средств достаточно широк – языки программирования, интегрированные средства типа генераторов отчетов. Для СУБД со внутренними языками программирования существуют варианты использования этого языка для генерации документов.
Создание информационного хранилища на основе высокопроизводительной СУБД с языком запросов SQL. Периодическая загрузка данных в хранилище из основных СУБД
В этом варианте предлагается использование технологии, получившей название «информационного хранилища» (ИХ). Для обработки разнообразных запросов, в том числе и от WWW-сервера, используется промежуточная БД высокой производительности (см. рис.2.16). Информационное наполнение промежуточной БД осуществляется специализированным программным обеспечением на основе содержимого основных баз данных (см. рис.2.17).
Этап 1 – перегрузка данных
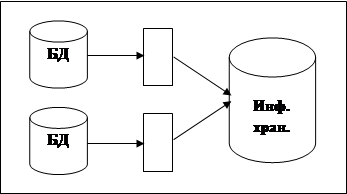 |
Рисунок 2.16
Этап 2 – обработка запросов
Рисунок 2.
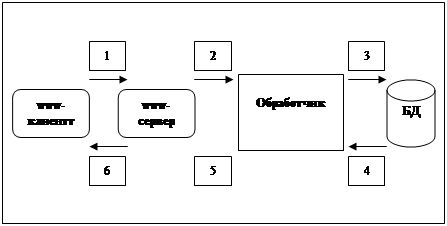 |
17
Данный вариант свободен ото всех недостатков предыдущей схемы. Более того, после установления синхронизации данных информационного хранилища с основными БД возможен перенос пользовательских интерфейсов на информационное хранилище, что существенно повысит надежность и производительность, позволит организовать распределенные рабочие места.
Несмотря на кажущуюся громоздкость такой схемы, для задач обеспечения WWW-доступа к содержимому нескольких баз данных накладные расходы существенно уменьшаются.
Основой повышения производительности обработки WWW-запросов и резкого увеличения скорости разработки WWW-интерфейсов является использование внутренних языков СУБД информационного хранилища для создания гипертекстовых документов.
Для загрузки содержимого основной БД в информационное хранилище могут использоваться все перечисленные решения (языки программирования, интегрированные средства), а также специализированные средства перегрузки, поставляемые с SQL-сервером и продукты поддержки информационных хранилищ.
15. База данных Информационно-методического центра «Сведения об образовательных учреждениях»
Назначение и предметная область
База данных предназначена для хранения данных об учебных заведениях города Екатеринбурга и доступна по адресу: http://base.eimc.ru.
| 2 |
№ школы: 109 Полное наименование: Муниципальное образовательное учреждение средняя общеобразовательная школа №109 с углубленным изучением предметов гуманитарно-педагогического цикла Ленинского р-на г. Екатеринбурга Адрес: 620146, г. Екатеринбург, ул. Волгоградская, 37б Телефоны: 28-17-52; 28-76-19; 28-08-05; 28-17-78 (музык школа) Тип компьютерной техники: Pentium 166 – 13 штук, локальная сеть есть Список профильных классов: Математические, гуманитарные, гуманитарно-педагогические Список кружков факультативов: 16. «Рукодельница»; 2. «Эстетика быта»; 3. «Мягкая игрушка»; 4. «Театральный»; 5. «Кукольный театр»; 6. «ИЗО»; 7. «Баскетбол»; 8. «Аэробика»; 9. «Музей»; 10. «История ремесла»; 11. «Юный агроном» Дополнительная информация: 17 лет школа сотрудничает с УРГПУ; 6 лет – с педколледжами; - При школе работает районный центр образовательных технологий; - В музее школы работает постоянно действующая выставка кружковцев школы; - Традицией школы стало проведение ежегодно: интеллектуально марафона, праздника «Золотые россыпи», - в честь победителей конкурсов и т.д. Интернет сайт: None Электронный адрес: None |
Рисунок 3.1
Анализ запросов показывает, что для наиболее оптимального поиска требуемого ресурса и отображения нужного следует выделить следующие критерии:
1. № школы
2. Полное наименование
3. Адрес
4. Телефоны
5. Тип компьютерной техники
6. Список профильных классов
7. Список кружков факультативов
8. Дополнительная информация
9. Интернет сайт
10. Электронный адрес
Пример заполненного по данным критериям ресурса можно увидеть на рисунке 3.1
Web-интерфейс позволяет любому желающему добавить информацию о каком либо учебном заведении, при этом оставив данные о себе. После проверки достоверности информации сотрудниками Информационно методического центра данные помещаются в базу данных. Такая система требует создания дополнительной базы данных содержащей в себе информацию о владельцах информационных ресурсов (внесших их). Эта база должна содержать в себе такие атрибуты, как:
1. Ф.И.О. владельца
2. E-mail владельца
3. Телефон
4. Адрес
5. Дата внесения ресурса в базу данных
Для поддержания связи с владельцем, в обязательные для заполнения поля включены “Ф.И.О.”., “E-mail” или “Телефон”. При не заполнении их в регистрации будет отказано. Содержимое поля “Дата внесения ресурса в базу данных” автоматически генерируется системой.
Проектирование базы данных.
Для организации базы данных «Сведения об учебных заведениях города Екатеринбурга» нам нужно создать две таблицы: «Учреждения» и «Владельцы ресурсов».
СОЗДАТЬ ТАБЛИЦУ Учреждения
ПЕРВИЧНЫЙ КЛЮЧ ( ID )
ПОЛЯ ( ID Целое,
Номер школы Целое,
Полное_наименование Текст,
Адрес Текст,
Телефон Текст,
Тип_компбютерной_техники Текст,
Список_профильных_классов Текст,
Список_кружков_факультативов Текст,
Дополнительная_информация Текст );
СОЗДАТЬ ТАБЛИЦУ Владельцы_ресурсов
ПЕРВИЧНЫЙ КЛЮЧ ( ID )
ПОЛЯ ( ID Целое,
Ф.И.О. Текст,
Текст,
Телефон Текст,
Адрес,
Дата внесения ресурса в базу данных Дата );
Устройство поисковой системы.
Поиск в системе происходит по средствам web-интерфейса. Поисковая форма содержит два поля: “Критерия вывода” и “Фильтр”. Поле “Фильтр” в свою очередь имеет следующие настройки: Вывод всех ресурсов, которые содержат значение поля “Фильтр”, Вывод всех ресурсов, которые не содержат значение поля “Фильтр” и настройка учета или не учета регистра.
Алгоритм поиска выглядит следующим образом:
Страницы: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24
