

 Реферат: Менеджер управления распределенными вычислениями в локальной сети
Реферат: Менеджер управления распределенными вычислениями в локальной сети
Реферат: Менеджер управления распределенными вычислениями в локальной сети
Ульяновский Государственный Университет
2000
Записка по курсовой работе
“Менеджер управления распределенными вычислениями в локальной сети”
Выполнил: студент группы ПМ-52
Никифоров Ю.В.
Преподаватель: Дулов Е.В.
2000
1. Модель среды параллельного программирования
В качестве физической архитектуры параллельного компьютера используется локальная сеть LAN Ethernet. Таким образом, параллельный компьютер состоит из некоторого количества процессоров P, соединенных между собой линией передачи данных.
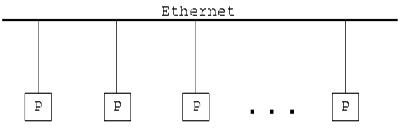
В модели параллельного программирования используются две абстракции: задача(task) и канал(channel).
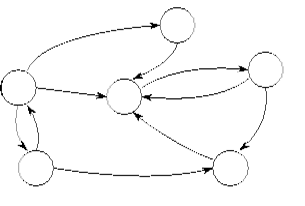
Данная модель характеризуется следующими свойствами:
1. Параллельное вычисление состоит из одного или более одновременно исполняющихся задач (процессов), число которых может изменяться в течение времени выполнения программы.
2. Задача - это последовательная программа с локальными данными. Задача имеет входные и выходные порты, которые служат интерфейсом к среде процесса.
3. В дополнение к обычным операциям задача может выполнять следующие действия: послать сообщение через выходной порт, получить сообщение из входного порта, создать новый процесс и завершить процесс.
4. Посылающаяся операция асинхронная - она завершается сразу, не ожидая того, когда данные будут получены. Получающаяся операция синхронная: она блокирует процесс до момента поступления сообщения.
5. Пары из входного и выходного портов соединяются очередями сообщений, называемыми каналами. Каналы можно создавать и удалять. Ссылки на каналы (порты) можно включать в сообщения, так что связность может измениться динамически.
6. Процессы можно распределять по физическим процессорам произвольным способами, причем используемое отображение (распределение) не воздействует на семантику программы. В частности, множество процессов можно отобразить на одиночный процессор.
2. Временные характеристики параллельной программы
Время выполнения программы – время, прошедшее с момента запуска первого процессора до момента завершения выполнения последнего (получения результата).
T = f (N, P, U, …)
где N - размерность задачи, P - количество процессоров, U - количество задач параллельного алгоритма.
Во время выполнения каждый процессор может находиться в трёх состояниях: вычисление (computation), обмен данными (communication) и ожидание (idle). Соответственно, определяется время нахождения процессора в каждом из них:
![]()
Следовательно, время выполнения T может быть определено следующим образом:
![]()
или
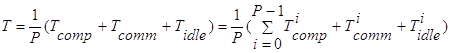
Время вычисления алгоритма Tcomp может быть равным времени выполнения соответствующего не распараллеленного (последовательного) алгоритма и зависит от размерности N задачи. Если параллельный алгоритм вносит дополнительные вычисления, тогда время вычисления зависит также и от количества задач U и процессоров P.
Время обмена данными алгоритма Tcomm это время, затраченное на прием и передачу данных между задачами. Существуют два вида обмена данными: между процессорами и внутри процессора. Первый тип обмена осуществляется между задачами находящимися на разных процессорах, т.е. по каналу связи. Второй тип обмена происходит, если взаимодействующие задачи находятся на одном процессоре, поэтому в данном случае обмен осуществляется гораздо быстрее, чем в первом, и по экспериментальным данным этим временем можно пренебречь.
Время передачи пакета данных между процессорами можно представить в виде следующего выражения:
![]()
где ts – время инициализации передачи, tw – время передачи единицы (слова) данных. Таким образом, в идеале имеем линейную зависимость времени передачи от длины данных.
Но в сети типа Ethernet для обмена данными для всех процессоров используется единственный канал связи. Если два процессора хотят передать данные в одно и то же время, реально будет передавать только один из них, а второй будет ожидать окончания передачи первого. Т.е. имеет место разделение канала связи во времени. Если S – количество конкурирующих процессоров нуждающихся в передаче данных, то предыдущая формула изменится следующим образом:
![]()
Таким образом, реальная пропускная способность канала равна S-1.
Время ожидания (простоя) алгоритма Tidle. Процессор может простаивать в одном из двух случаев:
· при отсутствии загруженных на него задач;
· при отсутствии входных данных задачи.
Во втором случае избавится от простаивания можно следующим образом. Когда задача блокируется в ожидании входных данных можно на данном процессоре запустить другую задачу, для которой имеются входные данные. Как только для первой задачи поступят данные прекратить выполнение второй. Данный метод оправдан только при низкой стоимости переключения задач. Также можно подключать разные каналы для одной и той же задачи при низкой стоимости данной операции.
Более удобной мерой качества параллельной программы, чем время выполнения, является эффективность. Она характеризует полноту использования алгоритмом ресурсов параллельного вычислительной среды независимо от размерности самой задачи. Относительная эффективность определяется как:
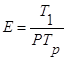
где T1 – время выполнения на одном процессоре, Tp – время выполнения на P процессорах.
Относительное ускорение:
![]()
- это коэффициент уменьшения времени выполнения на P процессорах.
3. Методы измерения временных характеристик в реальном времени
Имеется три вида методов сбора информации о производительности параллельной программы:
· рабочий профиль программы (execution profile) представляет собой общее время, проведенное в различных участках программы;
· счетчики событий или совокупного времени;
· трассировка событий.
Рабочий профиль формируется автоматически для каждого процессора. При этом используется метод выборки данных через фиксированные промежутки времени, поэтому точность измерения не столь высока. По результатам можно построить гистограмму рабочих величин, например, определить задачу, которая забирает наибольшую часть вычислительного времени параллельного алгоритма на текущий момент.
Счетчик представляет собой переменную, которая может быть увеличена каждый раз при наступлении определенного события. Счетчик может использоваться для подсчета количества вызовов данной процедуры, общего количества переданных или принятых сообщений, общего размера переданных или принятых данных для каждого процессора, задачи или канала. Некоторые счетчики встроены в библиотеки среды параллельного программирования, и можно заводит новые путем вставки соответствующих вызовов библиотеки в исходный код задач.
Другой вариант счетчика – интервальный таймер. Он может использоваться для точного измерения времени выполнения определенных участков кода программы (задачи). Поэтому с помощью таймера можно измерять такой критичный ресурс процессора как производительность.
Информация, накопленная счетчиками, может использоваться в рабочих профилях программы.
Трассировка событий предоставляет наиболее детальную низкоуровневую информацию о производительности параллельной программы. Эта информация представляет собой записи с отметкой о времени наступления события, типом события, именем задачи, взаимодействующей задаче и др.
Трассировка событий может использоваться для локализации источников простоя и временной перегрузки программы, и так называемых «узких мест» в каналах передачи данных.
Полученные трассировочные данные могут также использоваться в рабочем профиле программы и счетчиках.
4. Реализация
Метрики. Измеряемые параметры производительности программы будем называть метриками, по сути, они те же счетчики. Каждая метрика представляет собой целое беззнаковое 32-битное число или unsigned long. Для каждого канала, задачи и процессора имеется стандартный внутренний набор метрик, который вычисляется автоматически или с участием программиста задач. Также имеется дополнительный массив ячеек для нестандартных метрик, размер его ограничен.
Ссылка на ячейки производится путем указания номера ячейки, аналогично массивам, начиная с нуля.
Для вычисления метрик используются три абстракции:
Страницы: 1, 2
