

 Реферат: Архитектура IA-32
Реферат: Архитектура IA-32
В реализации процессоров Intel Pentium 4 и Intel Xeon, кэш трасс может хранить до 12 тысяч микрокоманд и выдавать до трех микрокоманд за цикл. Кэш трасс не хранит все микрокоманды необходимые для обработки в исполнительном ядре. В некоторых ситуациях, исполнительному ядру необходимо выполнить поток микрокода, вместо трасс микрокоманд, хранящихся в КЭШе трасс.
Процессоры Intel Pentium 4 и Intel Xeon оптимизированы для выполнения часто-используемых IA-32 инструкций, в то время как только некоторые инструкции вовлекают в процесс декодирования ROM-микрокода.
Предсказание ветвей
Предсказание ветвей очень важно для производительности процессоров с большим конвейером. Это позволяет процессору начать работу задолго до того как будет дотошно известен результат ветвления. Задержка при ветвлении – это расплата за неправильное предсказание ветвление. Для процессоров Intel Pentium 4 и Intel Xeon задержка при правильном предсказании может быть нулевой. Задержка же при неправильном предсказании может быть множество циклов, обычно она равна глубине конвейера.
Предсказание ветвей в микроархитектуре Intel NetBurst затрагивает все ближние ветвления (условные вызовы, безусловные вызовы, возвраты и тупиковые ветви). Но не затрагивает дальние переходы (дальние вызовы, неопределенные возвраты, программные прерывания).
Механизмы внедренные для более точного предсказания ветвей и затрат на их обработку:
· Возможность динамически предсказывать направление и точку ветвления, основанная на линейном адресе инструкции, используя буфер точек ветвления (BTB)
· Если нет возможности динамического предсказания или оно не правильное, то существует возможность статического предсказания результата основанного на замене цели: задняя ветвь берется за основную, а основная не берется.
· Возможность предсказания адресов возвратов, с помощью 16-разрядного стека адресов возвратов
· Возможность строить трассы инструкций по всей взятой ветви для избежания расплаты за неправильно предсказание
Статический предсказатель. Как только инструкция ветвления декодирована, направление ветви (вперед или назад) становиться известным. Если BTB нет упоминаний об этом ветвлении, статический предсказатель делает предсказание, основываясь на направлении ветви. Механизм статических предсказаний предсказывает задние условные цели (например, с отрицательным перемещением, такие как ветви оканчивающиеся циклом) как основные. Вперед направленные ветви предсказываются как не основные.
Для использования преимуществ передних-не-основных и задних-основных статических предсказаний, код должен быть упорядочен так, чтобы нежелательные цели находились в передних ветвях.
Буфер точек ветвлений. Если доступна история ветвлений, процессор может предсказать итог ветвления даже раньше, чем инструкция ветвления будет декодирована. Процессор использует таблицу историй ветвлений и BTB для предсказания направления ветвлений, основываясь на линейном адресе инструкции. Как только ветвь изъята, BTB обновляет адреса точек.
Стек возврата. Возвраты происходят всегда. Но с тех пор как процедура может быть вызвана из нескольких мест, технология предсказания одной точки не удовлетворяет потребностям. Процессоры Intel Pentium 4 и Intel Xeon стек возвратов, который может предсказывать адрес возврата, для нескольких мест вызова процедуры. Это увеличивает выгоду от использования развернутых циклов содержащих вызовы функции. Это так же ослабляет необходимость использования ближних процедур, так как уменьшена расплата за возврат из дальних процедур.
Даже если направление и адрес ветвления правильно предсказаны, взятая ветвь может снизить параллелизм в обычных процессорах. Предсказатель ветвлений позволяет ветви и ее цели сосуществовать в одной нити КЭШа трасс, максимизируя доставку инструкций из блока начальной загрузки.
Обзор исполнительного ядра
Исполнительное ядро разработано для оптимизации общей производительности путем более эффективного управления исполнением простых ситуаций. Аппаратное обеспечение спроектировано для выполнения частых операций в простых случаях как можно быстрее, за счет нечасто исполняемых операций. Некоторые части ядра могут предполагать, что текущее состояние сохраняется для возможности быстрого исполнения похожих операций. Если бы этого не было, машина бы стопорилась. Примером такой конструкции может служить управление хранением-для-загрузки (store-to-load). Если загрузка предсказана зависимой от хранения, она получает данные из этого хранилища и предварительно выполняется. Если же загрузка не зависит от хранения, загрузка задерживается до получения реальных данных из памяти, затем она выполняется.
Задержка инструкций и производительность
Суперскалярное исполнительное ядро содержит аппаратные ресурсы, которые могут выполнять множество микроопераций параллельно. Возможности ядра при использовании доступного параллелизма исполнительных блоков могут быть улучшены поддержкой программным обеспечением следующих возможностей:
· Выбор IA-32 инструкций так, чтобы они были декодированы меньше чем в четыре микрокоманды и/или имели меньшие задержки
· Упорядочивание IA-32 инструкций для сохранения доступного параллелизма с помощью минимизирования цепочек длинной зависимости и перекрытия задержек длинных инструкций
· Упорядочивание инструкций так, чтобы их операнды были готовы и их исполнительные блоки и выводные порты были свободны к моменту достижения ими диспетчера
Этот раздел рассматривает распределение портов, задержки выработки результатов и задержек вывода (так же относящиеся к производительности). Эти концепции формируют основу для помощи программному обеспечению в упорядочивании инструкций для увеличения параллельно выполняемых микрокоманд. Порядок команд поставляемых в ядро процессора далее поступает в ведение ресурсов машинного диспетчера.
Исполнительное ядро – это блок, реагирующий на постоянно изменяющуюся ситуацию в машине, реорганизуя микрокоманды для более быстрой обработки или откладывая их из-за занятости или ограниченности ресурсов. Переупорядочивающие инструкции в программном обеспечении позволяют более эффективно использовать аппаратные средства. Некоторые блоки не имеют конвейеров (имеется в виду, что микрокоманды не могут быть размещены в последовательных циклах и их производительность меньше одной микрокоманды за цикл). Количество микрокоманд ассоциированных с каждой инструкцией позволяет выбирать инструкции для генерации. Все микрооперации, вырабатываемые ROM-микрокода, вызывают экстренную нагрузку.
Исполнительные блоки и выводные порты
На каждом цикле ядро может посылать микрокоманды в один или несколько из четырех портов вывода. На микроархитектурном уровне операции хранения делятся на две группы:
1. операции хранения данных
2. операции хранения адресов
Четыре порта, через которые микрокоманды выводятся в исполнительные блоки и служащие для операций загрузки и хранения показаны на рисунке 4. Некоторые порты могут выводить до двух микрокоманд за такт. Они обозначены как исполнительные блоки двойной скорости.
Порт 0. В первой половине цикла, нулевой порт может вывести либо одну сдвиговую микрокоманду с плавающей точкой (сдвиг стека для плавающей точки, обмен между операндами с плавающей точкой или сохранение данных с плавающей точкой), либо одну из микрокоманд арифметико-логического устройства (арифметические, логические, ветвление или сохранение данных). Во второй половине цикла порт может вывести схожую микрокоманду АЛУ.
Порт 1. В первой части цикли первый порт может вывести либо одну из исполнительных операций с плавающей точкой (все исключительные сдвиговые операции с плавающей точкой, все операции SIMD), либо одну арифметическую АЛУ микрокоманду. Во второй части цикла порт может вывести одну схожую микрокоманду АЛУ.
Порт 2. Этот порт обеспечивает вывод одной загрузочной операции за цикл.
Порт 3. Этот порт обеспечивает вывод одной операции сохранения адреса за цикл.
Общая выводная мощность может варьироваться от нуля до шести микрокоманд за цикл. Каждый конвейер состоит из нескольких исполнительных блоков. Микрокоманда помещается в блок конвейера, отвечающий правильному типу операций. Например, целочисленный АЛУ и блок исполнения операций с плавающей точкой (сумматор, множитель или делитель) могут разделять один конвейер.
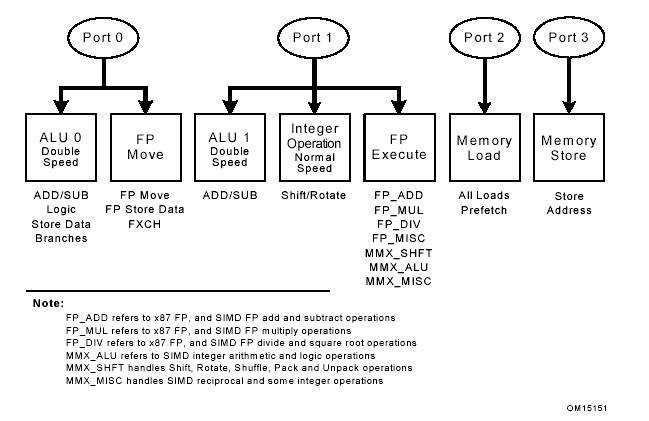
Рисунок 4. Исполнительные блоки и порты беспорядочного ядра
Кэши
Микроархитектура Intel NetBurst поддерживает до трех уровней встроенного КЭШа. По крайней мере, два уровня КЭШа встроены в процессоры, основанные на микроархитектуре Intel NetBurst. Процессоры Intel Xeon MP могут содержать кэш третьего уровня.
Кэш первого уровня (ближайший к исполнительному ядру) состоит из раздельных КЭШей инструкций и данных. Они включают кэш данных первого уровня и кэш трасс (улучшенный кэш инструкций первого уровня). Все остальные кэши делятся между инструкциями и данными.
Уровни в иерархии КЭШа не взаимовключающие. Факт того, что нить находиться на уровне N не означает, что она так же находиться на уровне N+1. Все кэши используют алгоритм замен псевдо-НЧИ (наименее часто используемые).
Таблица 1 приводит сравнительные параметры КЭШей всех уровней процессоров Pentium 4 и Xeon.
Таблица 1. Параметры кэша процессоров Pentium 4 и Intel Xeon
