

 Доклад: Параллельные машины баз данных
Доклад: Параллельные машины баз данных
Доклад: Параллельные машины баз данных
В конце второго тысячелетия человечество шагнуло из индустриальной эры в эру информационную. Если раньше главными были материальные ресурсы и рабочая сила, то теперь решающими факторами развития общества становятся интеллект и доступ к информации. В информационном обществе люди в основном будут заняты в сфере создания, распределения и обмена информации, а каждый человек сможет получить необходимые продукт или услугу в любом месте и в любое время.
По направлению к базам данных
Как известно, основной инструмент хранения и переработки информации - электронные вычислительные машины (ЭВМ). Переход к информационному обществу сопровождается лавинообразным ростом объемов информации, хранимой в них. Это в свою очередь порождает проблему эффективной организации и поиска информации. Для представления в машинах больших объемов данных используются технологии баз данных. База данных представляет собой совокупность структурированных и взаимосвязанных данных, хранимых более или менее постоянно в ЭВМ на магнитных (пока) носителях, и используемых одновременно многими пользователями в рамках некоторого предприятия, организации или сообщества. Для работы с базами данных используется специальное системное программное обеспечение, называемое СУБД (Система управления базами данных). Вычислительный комплекс, включающий в себя соответствующую аппаратуру (ЭВМ с устройствами хранения) и работающий под управлением СУБД, называется машиной баз данных.
Первые такие машины появились во второй половине 60-х годов ушедшего века. В настоящее время на рынок программного обеспечения поставляются сотни различных коммерческих СУБД практически для всех моделей ЭВМ. До недавнего времени большинство машин баз данных включали в себя только один процессор. Однако в последнее десятилетие возник целый ряд задач, требующих хранения и обработки сверхбольших объемов данных. Один из наиболее впечатляющих примеров решения задач такого типа - создание базы данных Системы наблюдения Земли. Эта система (Earth Observing System, EOS) включает в себя множество спутников, которые собирают информацию, необходимую для изучения долгосрочных тенденций состояния атмосферы, океанов, земной поверхности. Спутники поставляют на Землю 1/3 петабайт информации в год (petabyte - 1015 байт), что сопоставимо с объемом информации (в кодах ASCII), хранящейся в Российской государственной библиотеке. Полученная со спутников, она накапливается в базе данных EOSDIS (EOS Data and Information System) невиданных прежде размеров.
Другая грандиозная задача, тоже требующая использования сверхбольших баз данных, ставится в проекте создания Виртуальной астрономической обсерватории. Такая обсерватория должна объединить данные, получаемые всеми обсерваториями мира в результате наблюдения звездного неба; объем этой базы составит десятки петабайт. Очевидно, даже самые мощные однопроцессорные ЭВМ не справятся с обработкой этого потока.
Естественное решение проблемы обработки сверхбольших баз данных - использовать в качестве машин баз данных многопроцессорные ЭВМ, позволяющие организовать параллельную обработку информации. Интенсивные исследования в области параллельных машин были начаты в 80-х годах. В течение последних двух десятилетий такие машины проделали путь от экзотических экспериментальных прототипов, разрабатываемых в научно-исследовательских лабораториях, к полнофункциональным коммерческим продуктам, поставляемым на рынок высокопроизводительных информационных систем.
В качестве примеров успешных коммерческих проектов создания параллельных систем баз данных можно назвать DB2 Parallel Edition [1], NonStop SQL [2] и NCR Teradata [3]. Подобные системы объединяют до тысячи процессоров и магнитных дисков и способны обрабатывать базы данных в десятки терабайт. Тем не менее и в настоящее время здесь остается ряд проблем, требующих дополнительных научных изысканий. Одно из них - дальнейшее развитие аппаратной архитектуры параллельных машин. Как указывается в Асиломарском отчете о направлениях исследований в области баз данных [4], в ближайшее время крупные организации будут располагать базами данных объемом в несколько петабайт. Для обработки подобных объемов информации потребуются параллельные машины с десятками тысяч процессоров, что в сотни раз превышает их число в современных системах. Однако традиционные архитектуры параллельных машин баз данных вряд ли допускают простое масштабирование на два порядка величины.
Сила и слабость параллельных систем
В основе современной технологии систем баз данных лежит реляционная модель, предложенная Е.Ф.Коддом еще в 1969 г. [5]. Первые реляционные системы появились на рынке в 1983 г., а сейчас они прочно заняли доминирующее положение. Реляционная база данных состоит из отношений, которые легче всего представить себе в виде двумерных (плоских) таблиц, содержащих информацию о некоторых классах объектов из предметной области. В случае базы данных, хранящей список телефонных номеров, таким классом объектов будут абоненты городской телефонной сети. Каждая таблица состоит из набора однородных записей, называемых кортежами. Все кортежи в отношении содержат один и тот же набор атрибутов, которые можно рассматривать как столбцы таблицы. Атрибуты представляют свойства конкретных экземпляров объектов определенного класса. Примерами атрибутов отношения Телефонная_книга могут служить Фамилия, Номер, Адрес. Совокупность отношений и образует базу данных, которая в виде файлов специального формата хранится на магнитных дисках или других устройствах внешней памяти.
Над реляционными отношениями определен набор операций,
образующих реляционную алгебру. Аргументами и результатами реляционных операций
являются отношения. Запросы к реляционным базам данных формулируются на
специальном языке запросов SQL (ранее называемом SEQUEL) [6]. На рис.1 показан
пример запроса на языке SQL, выполняющего операции селекции и проекции. В нашем
случае из отношения Телефонный_справочник осуществляется выборка
(селекция) всех записей, у которых атрибут Фамилия принимает значение ‘Иванов’.
В результирующее отношение проецируются только столбцы Номер и Адрес.

Рис.1. Пример запроса на языке SQL, выбирающего из отношения Телефонная_книга номера телефонов и адреса всех абонентов с фамилией Иванов.
Если исходное отношение достаточно велико, выполнение операции селекции скорее всего потребует значительных затрат машинного времени. Для ускорения мы можем попытаться организовать параллельное выполнение запроса на нескольких процессорных узлах многопроцессорной системы. К счастью, реляционная модель наилучшим образом подходит для “распараллеливания” запросов. В самой общей форме этот процесс можно описать так. Каждое отношение делится на фрагменты, которые располагаются на различных дисковых устройствах. Запрос применяется не к отношению в целом, а к данным фрагментам. Каждый фрагмент обрабатывается на отдельном процессоре. Результаты, полученные на различных процессорах, затем объединяются (сливаются) в общее результирующее отношение, как это схематично показано на рис.2. Таким образом, разбивая отношение на n фрагментов в параллельной машине баз данных с n процессорными узлами, мы уменьшаем время выполнения запроса в n раз!
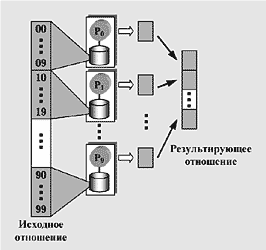
Рис.2. Параллельное выполнение запроса. Исходное отношение разбивается на фрагменты по первым двум цифрам телефонного номера. Каждый фрагмент имеет свои собственные диск для хранения и процессор для обработки. Результирующее отношение объединяет данные, поставляемые отдельными узлами системы.
Однако не все так просто, как может показаться сначала. Первая проблема, с которой мы столкнемся, - по какому критерию производить деление отношения на фрагменты? В нашем примере на рис.2 мы применили так называемое упорядоченное разделение, использующее первые две цифры телефонного номера в качестве критерия распределения кортежей по дискам. Но подобный способ разбиения отнюдь не идеален, так как в результате мы скорее всего получим фрагменты, существенно различающиеся между собой по размерам, а это в свою очередь может привести к сильным перекосам в загрузке процессоров. При неудачной разбивке отношения на фрагменты на один из процессоров может выпасть более 50% от общего объема нагрузки, что снизит производительность нашей многопроцессорной системы до уровня системы с одним процессором!
Известно несколько методов разбиения отношения на фрагменты в параллельной машине баз данных (см., например, [7]), однако ни один из них не может обеспечить сбалансированной загрузки процессоров во всех случаях. Следовательно, чтобы “распараллеливание” запросов в параллельной машине стало эффективным, мы должны иметь некоторый механизм, позволяющий выполнять перераспределение (балансировку) нагрузки между процессорами динамически, т.е. непосредственно во время выполнения запроса.
Другая серьезная проблема, связанная с использованием параллельных машин баз данных, возникает из-за ограниченной масштабируемости. В многопроцессорной системе процессоры делят между собой некоторые аппаратные ресурсы: память, диски и соединительную сеть, связывающую отдельные процессоры между собой. Добавление каждого нового процессора приводит к замедлению работы других, использующих те же ресурсы. При большом числе участников может возникнуть ситуация, когда они будут дольше ждать того или иного общего ресурса, чем работать. В этом случае говорят об ограниченной масштабируемости системы.
Само число процессоров и дисков влечет за собой и третью серьезную проблему, с которой мы столкнемся при создании параллельных машин, - проблему обеспечения отказоустойчивости системы. Действительно, вероятность выхода из строя магнитного диска в однопроцессорной системе не очень велика. Однако, когда наша параллельная система включает в себя несколько тысяч процессоров и дисков, вероятность отказа возрастает в тысячи раз. Это рассуждение применимо к любой массовой аппаратной компоненте, входящей в состав многопроцессорной системы. Поэтому для параллельных машин баз данных проблема отказоустойчивости становится особенно важной.
Страницы: 1, 2
